참고: Computer System A Programmers Perspective (3rd), Randal E. Bryan, David R. O’Hallaron, 김형신 번역, 피어슨에듀케이션코리아, 2016
- 개인적으로 공부하면서 지속적으로 정보를 추가, 수정, 삭제합니다.
- 정확하지 않은 부분 피드백 주시면 감사합니다.
- 본 포스팅은 컴퓨터 시스템 (줄여서 CSAPP) 교재를 강의와 함께 노트한 것입니다.
- 노란색 하이라이트는 블로그 주인의 생각 + 이해가 더 필요한 부분을 개인적으로 표시한 것입니다.
학습목표
- 기본적인 클라이언트-서버 프로그래밍 모델 이해하기
- 인터넷이 제공하는 서비스를 사용하는 클라이언트-서버 프로그램 작성하는 방법 이해하기
- 작지만 실제로 동작하는 tiny 웹 서버 개발하기
컴퓨터와 컴퓨터가 연결 된 것을 컴퓨터 네트워크라고 함.
이때 각각의 컴퓨터들은 맡은 역할이 있음.
배경지식
- 컴퓨터를 이루는 세 개의 레이어; 유저 모드, 커널 모드, 하드웨어
★★ 암기!
11.1 클라이언트-서버 프로그래밍 모델
0. 호스트, 서버, 클라이언트란?
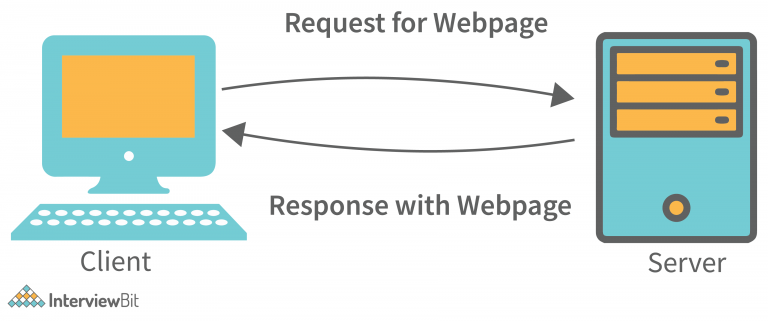
- 호스트
- 네트워크에서 호스트란 일반적으로 컴퓨터 또는 디바이스
- 컴퓨터나 장치를 구성하는 구성 요소 중 하나로, 네트워크에 연결되어 있고 네트워크상의 다른 컴퓨터나 장치와 통신할 수 있는 장치
- 서버와 클라이언트의 구분
- 서버와 클라이언트는 네트워크 상에서 연결 된 컴퓨터의 역할을 말함. 서버는 데이터를 제공하고, 클라이언트는 제공받은 데이터를 처리하는 역할
- 클라이언트는 서버에게 정보를 요청하는 컴퓨터
- 서버는 여러 클라이언트의 요청을 처리하는 컴퓨터
1. 클라이언트-서버 모델
- 모든 네트워크 응용 프로그램은 클라이언트-서버 모델에 기초
- 애플리케이션은 한 개 이상의 서버 프로세스와 한 개 이상의 클라이언트 프로세스로 구성
- 서버 프로세스
- 자원 관리
- 자원을 조작해 클라이언트를 위한 서비스 제공
- 예를 들어
- 웹 서버: 디스크 파일들 관리, 클라이언트를 대신해 이들을 가져오고 실행함
- FTP 서버: 클라이언트를 위해 저장하고 읽어오는 디스크 파일들을 관리
- 이메일 서버: 클라이언트를 위해서 읽고 갱신하는 스풀 파일을 관리
- 클라이언트 프로세스
- 서버에 접속해서 데이터나 서비스를 요청하고 응답을 받는 역할
- 서버 프로세스
2. 클라이언트-서버 트랜잭션transaction

- 클라이언트-서버 모델의 기본 연산
- 클라이언트로부터의 요청과 이에 대한 서버의 응답
- 다음의 네 단계로 구성
- 클라이언트가 서비스를 필요로 할 때, 클라이언트는 한 개의 요청request을 서버에 보내며 트랜잭션을 개시함
(e.g.: 웹 브라우저가 파일을 필요로 할 때, 웹 서버로 요청을 보냄) - 서버는 요청을 받고, 해석하고interpret, 자신의 자원들을 적절한 방법으로 조작
(e.g.: 웹 서버가 브라우저로부터 요청을 받을 때, 웹 서버가 디스크 파일을 읽음) - 서버는 응답response를 클라이언트로 보내고, 그 후에 다음 요청을 기다림
(e.g.: 웹 서버는 이 파일을 다시 클라이언트로 돌려보냄) - 클라이언트는 응답을 받고 이것을 처리함.
(e.g.: 웹 브라우저가 서버로부터 페이지를 한 개 받음 → 스크린에 보여줌)
- 클라이언트가 서비스를 필요로 할 때, 클라이언트는 한 개의 요청request을 서버에 보내며 트랜잭션을 개시함
3. 클라이언트-서버 모델과 호스트
- 클라이언트-서버 모델은 클라이언트와 서버의 호스트로의 매핑에 관계없이 동일함
- 클라이언트와 서버는 프로세스이며, machine이나 host가 아니다.
- 한 개의 host는 서로 다른 많은 클라이언트, 서버를 동시에 실행할 수 있음.
(※ e.g.: 로컬 네트워크에 연결된 컴퓨터가 파일을 전송하고 동시에 다른 컴퓨터로부터 파일을 전송받는 경우 해당 컴퓨터는 서버와 클라이언트의 역할을 동시에 할 수 있다.) - 클라이언트와 서버 트랜잭션은 동일하거나 다른 호스트에 존재할 수 있음.
11.2 네트워크
1. 네트워크 호스트의 하드웨어 구성

- 클라이언트와 서버는 종종 별도의 호스트에서 돌아가며, 컴퓨터 네트워크의 하드웨어 및 소프트웨어 자원을 사용하여 통신
- 호스트에게 네트워크는 또 다른 I/O 디바이스 中 하나 (키보드, 마우스, 모니터 같은…)
- 네트워크에서 전송 받은 데이터 → 네트워크 어댑터 → I/O 버스 → 메모리 버스 → 메모리
- 이 데이터는 대개 DMA 전송으로 복사 됨
(※ DMA 전송 방식: Direct Memory Access. 주변 장치들이 CPU의 개입 없이 메모리에 직접 접근하여 읽거나 쓸 수 있도록 하는 기능. CPU를 거쳐 메모리에 접근하는 방식보다 더 효율적.) - 마찬가지로 메모리에서 네트워크로 복사 됨
2. 네트워크 시스템은 계층구조로 이루어졌다

- LANlocal area network: (e.g.: 이더넷Ethernet; 가장 대중적인 LAN 기술)
- 이더넷 세그먼트
- 전선 & 허브hub로 구성
- 방이나 빌딩의 층 같이 작은 지역에 설치
- 호스트의 어댑터 ↔ 허브가 전선으로 연결
- 각 전선은 동일한 최대 비트 대역폭 (100Mb/s 혹은 1Gb/s)
- 허브는 각각의 포트에서 받은 모든 비트bit를 다른 포트에게 복사하여 전달하므로, 모든 호스트가 모든 비트를 볼 수 있음
- 이더넷 어댑터
- 어댑터의 비휘발성 메모리에 저장된 고유한(globally unique) 48비트의 주소를 가짐
- 프레임frame: 호스트는 프레임이라고 불리는 비트들을 세그먼트의 다른 호스트에게 보낼 수 있음
- 프레임 = 헤더 비트 + 데이터 비트(payload)
- 헤더 비트: 출발지, 목적지, 프레임의 길이를 식별할 수 있음
- 모든 호스트 어댑터는 프레임을 볼 수 있으나, 목적지 호스트만이 실제로 그것을 읽어들임
- 브릿지형 이더넷bridged Ethernets
- 전선들과 브릿지를 이용해 다수의 이더넷 세그먼트가 연결된 것으로, 더 큰 LAN을 구성함
- 전체 빌딩, 캠퍼스 규모로 설치
- 브릿지 ↔ 브릿지, 브릿지 ↔ 허브의 연결
- 각 선의 대역폭은 다를 수 있음 ⇒ 브릿지는 허브보다 더 높은 전선 대역폭
- 분산 알고리즘distributed algorithm을 통해, 어떤 호스트가 어떤 포트로부터 도달할 수 있는지를 배우고, 필요한 경우 선택적으로 한 포트에서 프레임을 복사하여 다른 포트로 전달함.
- 스위치와 브릿지의 차이 [2]

- 스위치는 멀티포트 브릿지
- 대부분의 브릿지는 2개 or 4개의 포트를 가지는 반면, 스위치는 수백의 포트를 가짐
- 브릿지는 소프트웨어 기반. 스위치는 하드웨어 기반; 스위치는 ASICs라는 칩을 이용하여 포워딩 결정을 내리며, 이 때문에 브릿지보다 훨씬 빠름
- 이더넷 세그먼트
- WANwide-area network과 라우터router
- “인터넷은 라우터의 집합체!”
- WAN: LAN보다 지리적으로 더 넓은 지역에서 운용되는 네트워크.
- 계층구조의 상부에서 여러 개의 서로 호환되지 않는 LAN들은 라우터라고 불리는 특별한 컴퓨터에 의해 연결 됨 → 네트워크 간 연결을 구성함(상호연결 네트워크)
- 각 라우터는 이들이 연결되는 각 네트워크에 대해 어댑터(포트)를 갖고 있음.
- 라우터는 스위칭을 한다; 데이터를 최종 도달 목적지까지 보내기 위해 라우터끼리 정보를 주고 받으며 데이터를 네트워크 교차로에서 어디로 보낼 지 결정함(라우팅 테이블을 이용하여)
- 상호연결 네트워크(internet; the Internet과 다름!)
- 네트워크는 서로 각기 다르고, 호환이 되지 않는 기술을 가진 여러 가지 LAN과 WAN으로 이루어짐
- 어떻게 특정 소스 호스트가 이러한 모든 호환되지 않는 네트워크들을 지나서 데이터를 다른 목적지 호스트로 전송할 수 있을까?
→ 프로토콜 소프트웨어의 계층 덕분
- 프로토콜 소프트웨어, 상호연결 네트워크 프로토콜(internet protocol; 소문자 internet임!)
- 각 호스트와 라우터들이 데이터를 전송하기 위해서 협력하는 방법에 대한 것
- 프로토콜은 다음의 두 가지 기본 기능을 제공해야 함
- 명명법Naming Scheme
- 각기 다른 LAN 기술은 주소를 호스트에 할당할 때 서로 다른 방법을 사용함
- → 프로토콜은 호스트 주소 형식을 통일시켜서 이런 차이점을 줄임
- 각 호스트는 자신을 유일하게 식별하는 인터넷 주소internet address를 최소한 한 개 할당 받음
- 전달기법delivery mechanism
- 네트워킹 기술은 각기 다르기에, 비트 인코딩 방법, 프레임 내에 이들을 패키징하는 방법이 서로 다름
- 프로토콜은 데이터 비트를 패킷packet이라는 단위로 나누어 전송하는 통일된 방법을 이용하여 이런 차이점을 줄임
- 패킷?: 헤더 + 데이터로 이루어짐
- 헤더: 패킷 크기 + 소스 호스트의 주소 + 목적지 호스트의 주소
- 데이터: 소스 호스트가 보낸 데이터 비트
- 명명법Naming Scheme
- 상호연결 네트워크에서 데이터가 하나의 호스트에서 다른 호스트로 이동하는 방법 여기 복잡해서 일단 패스
- 핵심은 캡슐화encapsulation
- 어려운 이슈
- 서로 다른 네트워크들이 서로 다른 최대 프레임 크기를 갖는다면?
- 라우터들은 어디로 프레임을 전달해야 할지 어떻게 아는가?
- 라우터들은 언제 네트워크 구조가 변경되는지 어떻게 알아내는가?
- 패킷이 손실된다면 어떻게 되는가?
11.3 글로벌 IP 인터넷
- 글로벌 IP 인터넷The global IP Internet
- 상호연결 네트워크를 구현한 것 중 가장 성공적이고 유명함
- 인터넷의 내부 구조는 계속 바뀌었을지언정, 클라이언트-서버 응용 모델은 지금까지 변하지 않음
- 인터넷 클라이언트-서버 애플리케이션의 기초적인 하드웨어 & 소프트웨어 구성

- 각각의 인터넷 호스트는 TCP/IPTransmission Control Protocol/Internet Protocol 프로토콜을 구현한 소프트웨어를 실행하며, 이는 거의 모든 현대 컴퓨터 시스템에서 지원 됨
- 클라이언트와 서버는 소켓 인터페이스와 I/O 함수들의 혼합을 사용하여 통신함 ☞ 11.4절
- 소켓 함수는 시스템 콜로 구현되며, 이는 커널에 들어가 TCP/IP에서 다양한 커널 모드 함수를 호출함
- TCP/IP는 프로토콜의 모음이며, 각각은 다른 기능을 제공함
- IP
- 기본적인 명명법을 제공하며, 데이터그램datagrams이라고 불리는 한 인터넷 호스트에서 다른 호스트에게 패킷을 전송하는 전달 기법을 제공
- IP의 전달기법은 데이터그램이 유실되거나 네트워크 상에서 중복되는 경우에 복구하려는 노력을 하지 않기에 안정적이지 못함
- UDP(Unreliable Datagram Protocol)
- IP에서 조금 확장되어, 데이터그램이 host to host가 아니라 process to process로 전송될 수 있게 함
(※ host to host 통신은 물리적인 실체인 host(PC나 라우터)간의 통신, process to process는 두 소프트웨어 사이의 통신)
- IP에서 조금 확장되어, 데이터그램이 host to host가 아니라 process to process로 전송될 수 있게 함
- TCP
- IP를 기반으로 구현된 복잡한 프로토콜로, 프로세스 간 안전한 양방향 연결을 제공함
- IP
- 프로그래머 관점에서 본 인터넷의 특징
- 인터넷은 전세계적인 호스트의 집합
- 각 호스트는 IP 주소IP addresses 라고 하는 고유한 32비트 이름을 가짐 → 호스트에 대한 식별자
- IP 주소의 집합은 인터넷 도메인 네임Internet Domain Name 이라고 부르는 식별자의 집합에 매핑
- 한 인터넷 호스트의 프로세스는 연결을 통해서 또 다른 인터넷 호스트의 프로세스와 통신할 수 있음
- IPv4와 IPv6
- IPv4: Internet Protocol Version4. 32비트 주소를 이용하는 오리지널 인터넷 프로토콜. 이 책에서는 IPv4를 다룸.
- IPv6: Internet Protocol Version6. IPv4 네트워크의 후속작으로, 128비트의 주소를 가짐. 하지만 여전히 대부분의 사용자들이 IPv4를 사용하고 있음.
11.3.1 IP 주소
/* IP address structure */
// 네트워크 프로그램은 IP 주소를 아래와 같은 *IP 주소 구조체*에 저장
struct in_addr
{
uint32_t s_addr; /* Address in network byte order (big-endian) */
};
- 엔디언Endianness 과 바이트 순서Byte order 란?[3]

- 엔디언: 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법. 빅 엔디언과 리틀 엔디언으로 나뉨
- 빅 엔디언: 큰 단위가 앞에 나옴
- 리틀 엔디언: 작은 단위가 앞에 나옴
- 미들 엔디언: 빅 엔디언, 리틀 엔디언 두 경우에 모두 속하지 않거나 둘을 모두 지원하는 경우
- 바이트 순서: 엔디언을 논할 때, 특히 바이트를 배열하는 방법을 말함. 크게 빅 엔디언, 리틀 엔디언으로 나뉨.
- 두 방법은 서로 다른 여러 아키텍쳐에서 공존하고 있으며, 둘 중 어느 한쪽이 더 좋거나 나쁘다고 알려져 있지 않음.
- x86 아키텍쳐가 리틀 엔디언을 사용하며, 이를 인텔 포맷이라 함
- 네트워크에서는 주소를 빅 엔디언으로 씀
- 엔디언: 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법. 빅 엔디언과 리틀 엔디언으로 나뉨
- IP 주소 구조체
- IP주소는 비부호형 32비트 정수unsigned 32-bit integer
- 네트워크 프로그램은 IP 주소를 위 코드와 같은 IP 주소 구조체에 저장함
- 인터넷 호스트들은 서로 다른 바이트 오더를 가질 수 있으므로, TCP/IP는 이를 통일시키기 위해 네트워크 패킷 헤더에 포함되는 IP 주소 같은 모든 정수형 데이터에 대해서 통일된 네트워크 바이트 순서network byte order(빅 엔디안 바이트 오더) 를 정의함
- → IP 주소 구조체의 주소는 호스트의 바이트 순서가 리틀 엔디안인 경우에도, 항상 네트워크 바이트 순서(빅 엔디안)로 저장
- 다음과 같은 함수들이 바이트 순서 간의 변환을 해줌 이 함수들은 중요한 것들일까… 모르겠다
11.3.2 인터넷 도메인 이름(Internet Domain Name)
- 인터넷 도메인 이름의 배경
- 인터넷 클라이언트와 서버는 서로 통신하며 IP 주소를 사용하지만, 숫자는 사람들이 기억하기 어려움
- 따라서 인터넷은 다음을 제공함: 도메인 이름들의 집합을 IP 주소 집합으로 매핑하는 메커니즘 + 사람들에게 친숙한 별도의 도메인 이름 집합
- 도메인 이름의 구조

- 계층 구조를 형성하며, 트리로 나타냄
- 각각의 도메인 이름은 계층 구조에서 자신의 위치를 인코드
- 트리의 노드를 따라 루트로 가면 도메인 이름이 표현 됨
- 서브 트리 = 서브 도메인
- 일단 어떤 조직이 2단계 도메인 이름을 받은 후에는, 서브 도메인내에서 어떠한 이름도 자유롭게 생성할 수 있음
- DNS(Domain Name System)
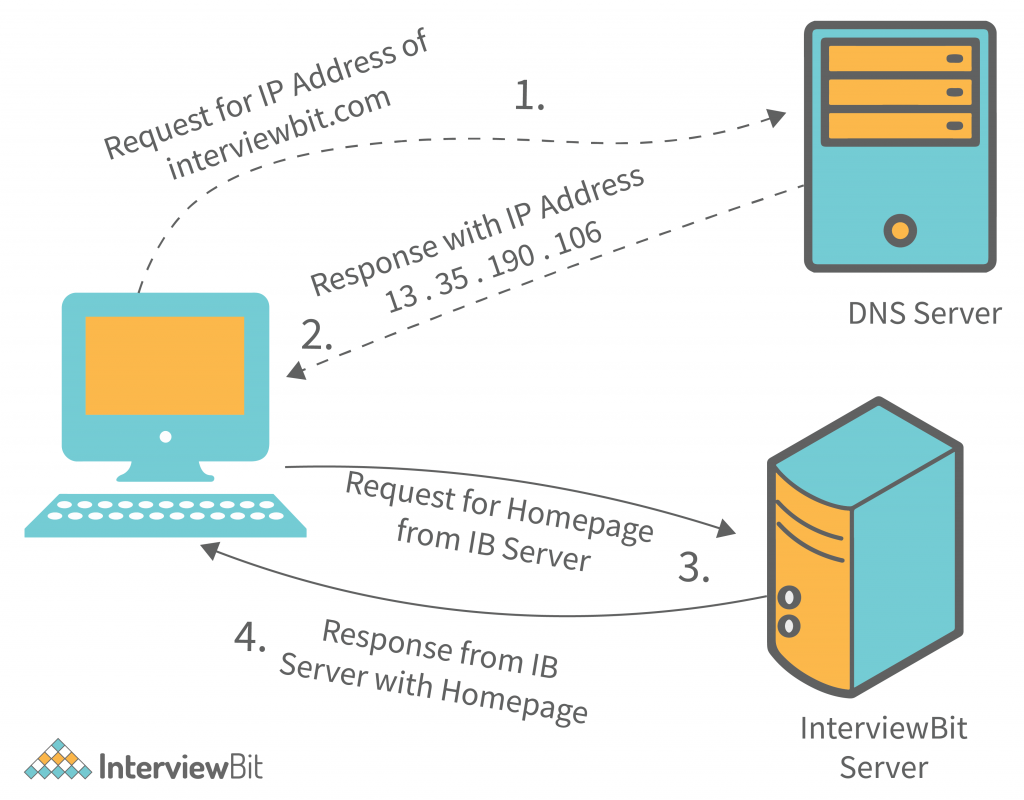 [4]
[4]
- 인터넷은 도메인 이름의 집합과 IP 주소 집합 사이에 매핑을 정의
- DNS는 이러한 매핑을 관리하는 전세계에 분산된 데이터베이스
- DNS 데이터베이스는 수백만 개의 호스트 엔트리로 구성되며, 이들 각각이 도메인 이름과 IP 주소 사이의 매핑을 정의함
(※ 호스트 엔트리: 컴퓨터의 IP 주소와 도메인 이름을 포함하는 정보)
- 리눅스의
NSLOOKUP프로그램- 도메인 이름과 연관된 IP 주소를 표시해주는 프로그램
- 도메인과 IP의 매핑
localhost- 각 인터넷 호스트는 도메인 이름
localhost를 가지고 있음 localhost란 프로그램이 실행되고 있는 로컬 컴퓨터를 가리키는 이름으로, 프로그램이 똑같은 컴퓨터에서 실행 중인 서버에 연결하려고 할 때 종종 사용 됨.localhost주소는 "컴퓨터가 자신의 네트워크 인터페이스를 통해 자신에게 보낸 데이터를 돌려보낸다"라는 뜻으로 루프백 주소loopback address라고 불리는127.0.0.1를 가리킴- 대부분의 운영 체제에서 이 IP 주소를 사용하여 컴퓨터 자신에 대한 네트워크 요청을 처리
- 이는 테스트와 디버깅에 편리한데, 서버 컴퓨터를 따로 마련할 필요 없이 스스로 서버를 돌리고 접속할 수 있게 도와주기 때문. → set up과 maintain 용이
- IP 주소
127.0.0.1을 사용하면 내 컴퓨터의 정확한 IP 주소를 알아내지 않고도 네트워크 인터페이스를 사용할 수 있지만, 다른 컴퓨터와의 네트워크 통신을 지원하지 않음. → 즉, 컴퓨터 내부의 장비와 소프트웨어만 접근할 수 있을 뿐, 외부로의 네트워크 연결은 지원하지 않음. localhost사용 예시- 웹 애플리케이션을 개발할 때, 로컬 컴퓨터에서 웹 서버를 실행할 수 있고, 이때 웹 브라우저에서 "localhost"라는 도메인 이름을 사용하여 그 서버에 접속 가능. 이는 원격 서버를 이용할 필요 없이 디버그와 테스트를 가능하게 해줌.
- 데이터베이스 서버를 실행할 때, 데이터베이스에서 나의 애플리케이션으로 접속하면서 "localhost"를 호스트 네임으로 사용할 수 있음. 이는 데이터베이스 서버의 호스트 이름이나 IP 주소를 알아낼 필요 없이, 애플리케이션이 로컬 컴퓨터에서 데이터베이스로 접근할 수 있게 해줌
- HTTP API를 테스트하기 위한 cURL 같은 툴을 사용할 때, 로컬 서버에 요청을 보내기 위해. "localhost"와 같은 도메인 이름을 사용할 수 있음. 이는 빠르게 원격 서버를 이용할 필요 없이 API를 테스트하고 디버그하게 해줌.
- 각 인터넷 호스트는 도메인 이름
- 일대일 매핑
- 다대일 매핑
- 다대다 매핑
※ 매핑이란?
컴퓨터 과학에서, 매핑이란 일반적으로 두 개의 데이터 집합을 서로 연결하거나 서로 상응하도록 만들어주는 프로세스를 가리킨다. 이는 다양한 기술과 알고리즘을 수반하며, 이는 매핑되는 데이터의 타입과 맥락에 따라 다르다. 예를 들어, 매핑이란 한 데이터 형식을 또 다른 데이터 형식으로 번역하는데 사용된다. 또 입력값을 그에 상응하는 다른 출력값 데이터로 변환하는데도 사용된다. 혹은 각기 서로 다른 두 개의 자료 구조의 원소들 간의 관계를 정립하는데도 사용된다. 매핑은 서로 다른 시스템간의 의사소통과 데이터 교환을 촉진하기 위해 사용될 수 있으며, 데이터 관리, 알고리즘, 프로그래밍 언어 등 컴퓨터 과학의 많은 영역에서의 기본적인 개념이다.
11.3.3 인터넷 연결(Internet Connections)
- 인터넷 연결 방식 및 특징
- 인터넷 클라이언트와 서버는 연결을 통해서 바이트 스트림the stream of bytes을 주고받는 방식으로 통신함
- 클라이언트와 서버는 소켓 인터페이스를 사용해 서로 연결됨 ☞ 11.4절
- 이 연결은 두 개의 프로세스를 연결한다는 점에서 점대점point-to-point연결
(※ 점대점 연결: 두 개의 장치를 직접 연결하는 방법. 간단하고 직관적이며 이해기 쉬운 방법 중 하나.) - 데이터가 동시에 양방향으로 흐를 수 있으므로 완전양방향full-duplex
- 소스 프로세스가 보낸 바이트 스트림이 결국 보낸 것과 동일한 순서로 목적지 프로세스에 수신되므로 안정적reliable
- 소켓(socket)
- 소켓이란?
- 네트워크 상의 두 컴퓨터 간에 데이터를 주고받기 위한 연결의 종단점end point (※ "접점"의 개념으로 바라보기)
- 프로그램 간 통신을 가능하게 해주는 소프트웨어 인터페이스
- 인터넷 상의 두 컴퓨터가 서로 통신할 수 있도록 하는 중요한 기능을 수행
- 소켓 주소
- 소켓은 인터넷 주소와 16비트 정수 포트로 이루어진 소켓 주소를 가짐;
address : port
(※ 이때 이 포트는 소프트웨어 포트로, 네트워크 스위치와 라우터에서의 하드웨어 포트와는 관련이 없음!)
- 소켓은 인터넷 주소와 16비트 정수 포트로 이루어진 소켓 주소를 가짐;
- 소켓 주소의 포트
- 클라이언트의 소켓 주소에 있는 포트: 클라이언트가 연결 요청을 할 때 커널이 자동으로 할당하며, 이것을 단기 포트ephemeral port라고 함
- 서버의 소켓 주소에 있는 포트: 대개 영구적으로 이 서비스에 연결 된 잘 알려진 포트well-known port
(e.g.: 웹 서버 → 포트 80, 이메일 서버 → 포트 25)- 잘 알려진 서비스 이름: 잘 알려진 포트를 갖는 각 서비스에 연관되어 이에 대응되는 이름들. 이러한 잘 알려진 이름과 포트들 간의 매핑은
/etc/services파일에 보관. ? 이게 어디
(e.g.: 웹 서비스 →http, 이메일 →smtp)
- 잘 알려진 서비스 이름: 잘 알려진 포트를 갖는 각 서비스에 연관되어 이에 대응되는 이름들. 이러한 잘 알려진 이름과 포트들 간의 매핑은
- 소켓이란?
- 소켓 쌍socket pair
- 연결은 두 개의 종단점의 소켓 주소에 의해 고유하게 식별 됨
- 이러한 두 개의 소켓 주소를 소켓 쌍이라고 하며, 튜플 형태로 나타냄;
cliaddr : cliport, servaddr : servport)☞ (클라이언트의 IP 주소 : 클라이언트의 포트, 서버의 IP 주소 : 서버의 포트)
- 인터넷 연결 예시

- 웹 클라이언트의 소켓 주소:
128.2.194.242:51213- 포트
51213은 커널이 할당한 단기 포트
- 포트
- 웹 서버의 소켓 주소:
208.216.181.15:80- 포트
80은 잘 알려진 포트 중 하나로, 웹 서비스와 관련 됨
- 포트
- 이제 이 둘의 소켓 주소가 주어졌으므로, 클라이언트와 서버 사이의 연결은 소켓 쌍에 의해 식별 됨
- 웹 클라이언트의 소켓 주소:
- 추가) 점대점 연결 외의 다른 연결 방식
가장 유명한 예로 브로드캐스트 연결이 있습니다. 브로드캐스트 연결은 하나의 송신자가 여러 대의 수신자에게 데이터를 전송하는 방식입니다. 이는 네트워크에서 기본적인 개념으로, 예를 들어 라디오 방송과 같이 여러 대의 리시버에게 신호를 전송하는 경우에 이용할 수 있습니다. 다른 연결 방법으로는 멀티캐스트 연결, 그래픽 연결 등이 있습니다. 이들은 모두 네트워크에서 중요한 개념이며, 서로 다른 목적과 용도에 맞게 사용됩니다.
11.4 소켓 인터페이스The Sockets Interface

- 소켓 인터페이스란?
- 소켓을 사용하기 위한 네트워크 소프트웨어
- 네트워크 애플리케이션을 만들기 위한 Unix I/O 함수들과 함께 사용하는 함수들의 집합
- 소켓 식별자를 열고 닫기 위한 함수들을 제공
- 클라이언트와 서버는 이 소켓 식별자를 서로 읽고 쓰는 방식으로 통신함
- 거의 모든 현대 운영체제 시스템에서 구현 됨
(e.g.: 윈도우즈의 Winsock, 리눅스의 Berkeley sockets 등)
11.4.1 소켓 주소 구조체
- 리눅스 커널의 관점에서 소켓은 통신을 위한 end point
- unix 프로그램의 관점에서 소켓은 대응하는 식별자corresponding descriptor를 가진 열린 파일
- 소켓 주소 구조체란, 소켓을 식별하기 위해 사용되는 자료 구조
- 소켓을 식별하는데 사용되는 소켓 식별자를 저장하는데 사용 됨
- 소켓의 프로토콜 종류, 주소 패밀리, 포트 번호, IP 주소 등의 정보를 포함
/* IP socket address structure */
struct sockaddr_in {
uint16_t sin_family; /* Protocol family (always AF_INET) */
uint16_t sin_port; /* Port number in network byte order */
struct in_addr sin_addr; /* IP address in network byte order */
unsigned char sin_zero[8]; /* Pad to sizeof(struct sockaddr) */
};
/* Generic socket address structure (for connect, bind, and accept) */
struct sockaddr {
uint16_t sa_family; /* Protocol family */
char sa_data[14]; /* Address data */
};
11.4.2 socket 함수
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
// Returns : nonnegative descriptor if OK, −1 on error
- 소켓 식별자socket descriptor 를 만들기 위해(= 소켓을 만들기 위해) 클라이언트와 서버가 호출하는 함수 (※ 소켓은 클라이언트, 서버 각각 필요함)
- 리턴 값:
clientfd식별자clientfd식별자란?: client file descriptor를 의미. 파일 디스크립터는 운영 체제에서 파일을 나타내는 숫자 값. 클라이언트 파일 디스크립터는 클라이언트 측의 파일을 의미하며, 네트워크 프로그래밍을 할 때 서버와 클라이언트가 통신할 때 사용됨
- 하드코딩보다
getaddrinfo를 이용해socket의 인자를 제공하는 것이 좋음 - 추가) 식별자descriptor란?
- 디스크립터는 운영 체제에서 파일을 나타내는 숫자 값
- 일반적으로 파일을 열거나 접근할 때 운영 체제는 그 파일에 대한 디스크립터를 반환함
- 네트워크 프로그래밍을 할 때는 클라이언트와 서버가 통신할 때 디스크립터를 사용
- 네트워크에서 디스크립터는 클라이언트와 서버의 연결을 나타내는 숫자 값이며, 이를 통해 서로의 데이터를 주고 받음
- 식별자를 사용하는 이유는?
- 파일을 쉽게 제어하기 위해
- 디스크립터는 파일을 나타내는 숫자 값이므로, 각각의 파일을 구분하기 쉽습니다.
- 디스크립터는 운영 체제에서 관리하기 때문에, 응용 프로그램이 파일을 열고 닫고 접근하는 것을 운영 체제가 대신 해줍니다.
- 디스크립터가 없다면 파일을 열고 닫고 접근하는 것을 운영 체제가 대신 해주지 않아 응용 프로그램이 직접 관리해야 하게 됩니다. 따라서 응용 프로그램이 더 많은 코드를 작성해야 하고, 코드가 복잡해지고, 오류가 발생할 확률이 높아질 것입니다.
- 네트워크 프로그래밍을 용이하게 하기 위해
- 디스크립터는 네트워크 프로그래밍을 할 때 클라이언트와 서버가 통신할 때 사용할 수 있습니다.
- 또한 네트워크 프로그래밍을 할 때도 디스크립터가 없으면 클라이언트와 서버가 서로의 데이터를 주고 받기 어렵고, 프로그래밍이 복잡해질 것입니다.
- 파일을 쉽게 제어하기 위해
11.4.3 connect 함수
#include <sys/socket.h>
int connect(int clientfd, const struct sockaddr *addr,
socklen_t addrlen);
// Returns: 0 if OK, -1 on error
- 클라이언트가 서버와 연결하기 위해 호출하는 함수
- 소켓 주소
addr를 가진 서버와 인터넷 연결을 시도 (※ 서버의 소켓과 연결 시도) - 연결이 성공할 때 까지 블록되어 있거나 에러 발생
- 성공시 0을 반환하며,
clientfd식별자를 읽거나 쓸 수 있게 됨 - 다음과 같은 소켓 쌍으로 연결을 규정;
(x:y, addr.sin_addr:addr.sin_port)x는 클라이언트의 IP 주소,y는 클라이언트 호스트의 클라이언트 프로세스를 유일하게 식별하는 단기 포트
getaddrinfo를 이용해connenct의 인자를 제공하는 것이 좋음
11.4.4 bind 함수
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
// Returns : 0 if OK, -1 on error
- 남아있는 소켓 함수
bind,listen,accept는 서버가 클라이언트와 연결을 수립하기 위해 사용 - 커널에게
addr에 있는 서버의 소켓 주소를 소켓 식별자sockfd와 연결하라고 함 이때 sockfd는 클라이언트 소켓인가? getaddrinfo를 이용해bind의 인자를 제공하는 것이 좋음
11.4.5 listen 함수
#include <sys/socket.h>
int listen(int sockfd, int backlog);
// Returns: 0 if OK, −1 on error
- 클라이언트는 연결 요청을 개시하는 능동적 개체, 서버는 클라이언트로부터의 연결 요청을 기다리는 수동적 개체
- 커널은
socket함수가 만든 소켓 식별자가 클라이언트 쪽의 연결 종단점의 능동 소켓active socket이라고 가정(즉, 클라이언트의 소켓이라고 디폴트 가정) listen함수는sockfd를 이러한 클라이언트의 능동 소켓에서 서버의 듣기 소켓listening socket으로 변환하며, 듣기 소켓은 클라이언트로부터의 연결 요청을 수락할 수 있음 (즉,listen함수는 소켓을 서버 소켓으로 설정함)listen함수는 연결을 기다리는 대기열을 생성 → 클라이언트가 연결을 요청할 때까지 그 대기열에 연결을 추가함backlog인자는 커널이 요청들을 거절하기 전에 큐에 저장해야 하는 연결의 수에 대한 정보로, 대개 1024처럼 큰 값으로 설정
11.4.6 accept 함수
#include <sys/socket.h>
int accept(int listenfd, struct sockaddr *addr, int *addrlen);
// Returns: nonnegative connected descriptor if OK, −1 on error
- 서버는
accept함수를 호출하여 클라이언트로부터 연결 요청을 기다림 - 클라이언트로부터의 연결 요청이 듣기 식별자
listenfd에 도달하기를 기다림 →addr내의 클라이언트의 소켓 주소를 채움 → Unix I/O 함수를 사용해 클라이언트와 통신하기 위해 사용될 수 있는 연결 식별자connected descriptor를 리턴함 - 듣기 식별자와 연결 식별자 구분
- 이 두 개념의 차이는 소켓이 서버와 연결되었는지 아닌지의 여부를 나타내며, 소켓의 상태를 구분함
- 듣기 식별자는 클라이언트의 접속을 기다리는 상태의 네트워크 소켓. 클라이언트 연결 요청에 대한 끝점으로, 한번 생성되며 서버가 살아있는 동안 계속 존재함.
- 연결 식별자는 이미 서버와 연결되어 데이터를 주고 받는 상태의 네트워크 소켓. 클라이언트와 서버 사이에 성립된 연결의 끝점으로, 서버가 연결 요청을 수락할때마다 생성되며, 서버가 클라이언트에 서비스하는 동안에만 존재함.
- 이 둘을 구분함으로서 많은 클라이언트 연결을 동시에 처리할 수 있도록 하는 동시성 서버를 만들 수 있음
11.4.7 호스트와 서비스 변환
- 리눅스의
getaddrinfo,getnameinfo함수- 이진 소켓 주소 구조체들과 호스트이름, 호스트주소, 서비스이름, 포트번호들 사이에 앞뒤로 변환해줌
- 소켓 인터페이스와 함께 이용하며 특정 IP 프로토콜의 버전에 의존하지 않는 네트워크 프로그램을 작성하게 해줌
getaddrinfo함수: 호스트이름, 호스트주소, 서비스 이름, 포트번호의 스트링 표시를 소켓 주소 구조체로 변환함getnameinfo함수:getaddrinfo의 반대. 소켓 주소 구조체를 대응되는 호스트와 서비스이름 스트링으로 변환
11.4.8 소켓 인터페이스를 위한 도움함수들
- 클라이언트와 서버가 이용할 수 있는 보다 상위수준의 도움함수
open_clientfd,open_listenfd open_clientfd함수: 클라이언트는open_clientfd를 호출해 서버와 연결을 설정함open_listenfd함수: 서버는open_listenfd함수를 호출해 연결 요청을 받을 준비가 된 듣기 식별자를 생성
11.4.9 예제 Echo 클라이언트와 서버
- echo 서버란?
- echo 서버는 전송된 데이터를 그대로 수신한 클라이언트에게 다시 전송하는 서버
- 즉, 클라이언트가 서버에 데이터를 전송하면 서버는 그 데이터를 그대로 수신하고, 그것을 다시 클라이언트에게 전송
- 예를 들어, 클라이언트가 "Hello, Server!"라는 메시지를 전송하면 서버는 "Hello, Server!"라는 메시지를 수신하고, 그것을 클라이언트에게 다시 전송
- 이를 이용하면 서버와 클라이언트의 연결이 잘 되었는지 테스트할 수 있음
- 이렇게 한 번에 한 개씩의 클라이언트를 반복해서 실행하는 이런 종류의 서버를 반복서버iterative server라고 함
- echo 서버 구현
echoclient.c파일: Echo 클라이언트의 메인 루틴- 서버와의 연결을 수립
- 클라이언트는 표준 입력에서 텍스트 줄을 반복해서 읽는 루프에 진입
- 서버에 텍스트 줄 전송
- 서버에서 echo 줄을 읽어 그 결과를 표준 출력으로 프린트
- 루프는
fgets가 EOF 표준 입력을 만나면 종료 → 유저가 Ctrl + D 입력 or 파일로 텍스트 줄 모두 소진 - 서버에 EOF 노티스 전송
- 서버는
rio_readlineb함수에서 리턴 코드 0을 받으면 이 사실을 감지
- 루프가 종료한 후에 클라이언트는 식별자를 닫음 → 클라이언트 종료
- 열었던 모든 식별자를 명시적으로 닫아주기 위해 관습적으로
Close(clientfd)
echoserveri.c파일: 반복적인 echo 서버 메인 루틴- 듣기 식별자 오픈
- 무한 루프 진입
- 각각의 반복실행은 클라이언트로부터 연결 요청 기다림
- 도메인이름과 연결된 클라이언트의 포트 출력
- 클라이언트를 서비스하는 echo 함수를 호출
- echo 루틴이 리턴한 후, 메인 루틴은 연결 식별자를 닫음
- 클라이언트와 서버가 자신의 식별자를 닫은 후 연결 종료
echo.c파일: 텍스트 줄을 읽고 echo 해주는 echo 함수rio_readline함수가 EOF를 만날 때까지, 텍스트 줄을 반복해서 읽고 print
- 추가) 연결 시에 EOF의 의미
- EOF라는 문자가 존재하는 것은 아니고, EOF는 커널이 감지하는 조건. 애플리케이션은 read 함수에서 9을 리턴 코드로 받으면 EOF 조건을 알게 됨.
- EOF는 디스크 파일에 대해서 현재 파일 위치가 파일 길이를 넘어가면 발생
- 인터넷 연결에서는 어떤 프로세스가 자신의 연결의 끝점을 닫을 때 EOF가 발생
- 연결의 다른 끝에 있는 프로세스는 스트림의 마지막 바이트를 지나서 읽으려고 할 때 EOF를 감지함
11.5 웹 서버
11.5.1 웹 기초

- HTTPHyptertext Transfer Protocol
- 웹 클라이언트와 서버는 HTTP라고 하는 텍스트 기반 애플리케이션 수준 프로토콜을 사용해 서로 통신함
- 웹 클라이언트(=브라우저)는 서버로의 인터넷 연결을 오픈하고 컨텐츠를 요청함 → 서버는 요청한 컨텐츠로 응답하고, 그 후에 연결을 닫음 → 브라우저는 컨텐츠를 읽고 이것을 스크린에 보여줌
- HTMLHyptertext Markup Language
- 웹 컨텐츠는 HTML이라는 언어로 작성될 수 있음
- HTML 페이지(프로그램)은 태그(명령들)을 포함하고 있어서 브라우저에게 여러가지 텍스트와 그래픽 객체를 페이지에 어떻게 표시할지 알려줌
- HTML 페이지는 어떤 인터넷 호스트에게 저장된 컨텐츠로 이동할 수 있는 포인터(하이퍼링크)를 포함할 수 있음
11.5.2 웹 컨텐츠
- 웹 컨텐츠란
- 웹 클라이언트(e.g.: 웹 브라우저)가 서버에 요청을 보내면, 서버는 요청에 해당하는 컨텐츠(e.g.: HTML 문서, 이미지 파일 등)를 웹 클라이언트에게 전송함
- 이 때 서버는 컨텐츠와 관련된 MIMEMultipurpose Internet Mail Extensions 타입(예를 들어, “text/html” 또는 “image/jpeg”)을 갖는 바이트 배열을 전송 → 이를 보고 웹 클라이언트는 전송받은 데이터를 어떻게 처리해야 할지 알 수 있음
(※ MIME 타입: 웹 컨텐츠의 종류를 나타내는 것으로, 웹 브라우저가 어떤 종류의 데이터를 전송받았을 때 어떻게 처리해야 할지 알려주는 역할을 함. 예를 들어, 웹 브라우저가 HTML 문서를 전송받았을 때는 "text/html"이라는 MIME 타입을 가지며, 이미지 파일을 전송받았을 때는 “image/jpeg” 또는 "image/png"와 같은 MIME 타입을 가짐.)
- 웹 서버가 클라이언트에게 컨텐츠를 제공하는 방법
- 디스크 파일을 가져와서 그 내용을 클라이언트에게 보냄
 [6]
[6]
- 이때 디스크 파일을 정적 컨텐츠라고 함
※ e.g.) 웹 페이지에 포함 된 이미지, HTML 파일 등 - 파일을 클라이언트에게 돌려주는 작업은 정적 컨텐츠를 처리한다 라고 함
- 이때 디스크 파일을 정적 컨텐츠라고 함
- 실행파일을 돌리고, 그 출력값을 클라이언트에게 보냄

- 이때 실행파일이 런타임으로 만든 출력값을 동적 컨텐츠라고 함
※ e.g.) 날씨 정보 받아오기, - 프로그램을 실행하여 그 결과를 클라이언트에게 보내주는 과정을 동적 컨텐츠를 처리한다라고 함
- 이때 실행파일이 런타임으로 만든 출력값을 동적 컨텐츠라고 함
- 디스크 파일을 가져와서 그 내용을 클라이언트에게 보냄
- URL
- URL이란?
- 웹 서버가 리턴하는 모든 내용들은 서버가 관리하는 파일에 연관되며, 이 파일은 각각 URL(Universal Resource Locator)라고 하는 고유의 이름을 가짐
- e.g.)
https://www.google.com:80/index.html이라는 URL은 포트 80에서 듣고 있는(listen) 웹 서버가 관리하는 인터넷 호스트www.google.com의/index.html이라는 HTML 파일을 지정함
- e.g.)
- 포트 번호는 옵션이며, 디폴트는 잘 알려진 HTTP 포트 80
- 실행파일을 위한 URL은 파일 이름 뒤에 프로그램의 인자를 포함할 수 있음
?문자: 파일명과 인자를 구분&문자: 각 인자 구분- e.g.)
http://bluefish.ics.cs.cmu.edu:8000/cgi-bin/adder?15000&213은/cgi-bin/adder라는 실행 파일을 식별하고 이 파일은15000과213라는 두 개의 인자와 함께 호출됨
- 웹 서버가 리턴하는 모든 내용들은 서버가 관리하는 파일에 연관되며, 이 파일은 각각 URL(Universal Resource Locator)라고 하는 고유의 이름을 가짐
- URL의 접두어와 접미어
- 접두어:
https://www.google.com:80어떤 종류의 서버에 접속하고, 어디에 서버가 있고, 서버의 무슨 포트를 듣고 있는지 결정 - 접미어:
/index.htm서버가 자신의 파일 시스템 상의 파일을 검색하고, 이 요청이 정적 혹은 동적 컨텐츠에 대한 것인지를 결정.
- 접두어:
- URL과 URI의 차이
- URI는 웹에서 자원을 식별하기 위해 사용되는 문자열로, URI에는 두 가지 유형의 식별자가 존재: URL과 URN.
- URL은 웹에서 자원을 식별하기 위해 사용되는 특정한 타입의 URI로, 프로토콜(“http” 같은), 도메인명이나 IP 주소(www.주소.com), 파일이나 자원 경로(/index.html)로 구성되어 있음
- URL이란?
11.5.3 HTTP 트랜잭션

- HTTP 요청
- 요청 라인 + 요청 헤더 + 빈 텍스트 줄
- 헤더에 HTTP 메소드, URI, 버전 등이 담김
- HTTP 메소드
- GET: 가장 많이 이용하는 메소드. GET 메소드는 서버에게 URI(Uniform Resource Identifier) 에 의해 식별되는 내용을 리턴할 것을 지시함.
- POST
- OPTIONS
- HEAD
- PUT
- DELETE
- TRACE 등
- GET과 POST의 차이
 [8]
[8]
- HTTP 응답
- HTTP 요청과 비슷함
- 헤더에 HTTP 버전, 상태 코드, 상태 메시지 등이 담김
11.5.4 동적 컨텐츠의 처리
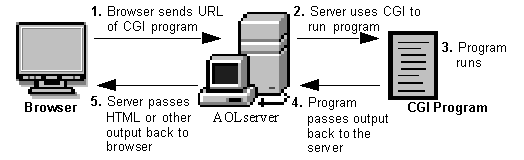
- 동적 컨텐츠를 웹 페이지에 표현하려면? 다음과 같은 질문들! (e.g.: 로그인 정보를 서버에 어떻게 전달?)
- 어떻게 클라이언트가 프로그램의 인자들을 서버에 전달하는가?
- 어떻게 서버는 이 인자들을 자신이 만든 자식 프로세스들에게 넘겨주는가?
- 어떻게 서버는 컨텐츠를 만들어낼 자식 프로세스에게 다른 정보를 전달하는가?
- CGICommon Gateway Interface
- CGI는 웹 애플리케이션 같은 외부 프로그램을 웹 서버에서 실행시키기 위한 표준.
- 웹 서버가 CGI 프로그램에 대한 요청을 받으면, 그것은 프로그램을 실행하고 클라이언트에게 출력값을 줌.
- CGI 프로그램의 출력값은 HTML, XML 혹은 그밖의 텍스트 기반 데이터.
- 오늘날에도 여전히 CGI는 널리 사용되지만, 더 새로운 기술인 서버-사이드 JS, PHP등에 의해 많이 대체되었다고 함.
- 어떻게 클라이언트는 서버에게 프로그램 인자를 전달하는가?
- GET 요청 이용하기
- GET 요청을 위한 인자는 URL의 일부로서 URI로 전달 됨 (
?문자,&문자)- 빈칸은 인자들 사이에 허용되지 않음
- 다른 특수 문자들도 비슷하게 적용 됨
- 서버사이드 프로그램은 이러한 URI를 parsing하여 인자에 접근함
- GET 요청을 위한 인자는 URL의 일부로서 URI로 전달 됨 (
- POST 요청 이용하기
- 클라이언트는 request body에 인자를 포함할 수 있고, 서버-사이드 프로그램은 그 request body를 읽음으로서 그 인자에 접근할 수 있음.
- 보통 인자 정보가 민감한 정보거나, 많은 양의 데이터를 서버에 전달할 때 사용함.
- WebSockets 같은 서버-사이드 기술
- 클라이언트와 서버가 실시간으로 통신할 수 있는 방법 제공.
- 양방향으로 데이터 전송을 허용함. 더 유연하고 동적으로 데이터를 교환하게 하며, 더 복잡하고 상호적인 애플리케이션에서 적합.
- GET 요청 이용하기
- 어떻게 서버는 자식 프로세스에게 인자들을 넘겨주는가?

- 서버가 다음과 같은 요청을 받았을 때;
GET /cgi-bin/adder?15000&213 HTTP/1.1fork를 호출해 자식 프로세스를 생성- →
execve를 호출해서/cgi-bin/adder프로그램을 자식의 컨텍스트에서 실행 (이때,adder같은 프로그램들은 종종 CGI 프로그램이라고 부르며, 이는 이들이 CGI 표준의 규칙을 준수하기 때문) execve를 호출하기 전에 자식 프로세스는 CGI 환경변수 QUERY_STRING을 "15000&213"으로 설정- →
adder프로그램은 런타임에 이 값을 참조함
- 추가)
fork와execve를 호출하면 무슨 일이 일어나는가?fork는 현재의 프로세스를 복제하는 기능을 가지고 있습니다. 따라서fork를 실행하면 현재의 프로세스가 복제되어 새로운 프로세스가 생성됩니다. 그리고execve를 실행하면 새로운 프로세스는 주어진 파일을 실행하게 됩니다. 따라서fork를 실행하고execve를 실행하면 현재의 프로세스가 복제되어 새로운 프로세스가 생성되고, 새로운 프로세스는 주어진 파일을 실행하게 됩니다.
- 서버가 다음과 같은 요청을 받았을 때;
- 어떻게 서버는 자식 프로세스에게 컨텐츠를 생성하기 위해 필요로 할지도 모르는 정보들을 넘겨주는가?
- CGI는 CGI 프로그램이 실행될 때 설정되어 있어야 하는 다른 환경변수의 개수를 정의 해놓음.
- 자식 프로세스는 자신의 출력값을 어디로 보내는가?
- CGI 프로그램은 자신의 동적 컨텐츠를 표준 출력(stdout)으로 보냄
- 이 표준 출력을 클라이언트와 연계된 연결 식별자로 가도록 재지정
- 그래서 CGI 프로그램이 표준 출력으로 쓰는 모든 것은 클라이언트로 직접 가게 됨
- 추가) 환경변수는 무엇이고 왜 그것이 필요한가?
- 환경변수는 프로그램이나 스크립트가 실행될 때 그것들에게 전달되는 값이다.
- 환경변수는 프로그램이나 스크립트가 적절히 실행되기 위해 필요로 하는 정보를 특정하는 방법을 제공한다. 예를 들어 프로그램이 접근해야 하는 파일의 위치, 디렉토리의 위치.
- 환경변수는 다양한 정보를 저장하기 위해 사용된다. 즉, 시스템 설정이나, 유저별 설정, 특정한 프로그램이나 스크립트에 한정적인 설정 같은 것.
- 환경 변수는 종종 운영체제에 의해서 설정됨. 하지만 유저나 프로그램에 의해서 수정되거나 세팅될 수 있음.
- 우리가 환경 변수를 필요로 하는 이유 중 하나는 프로그램과 스크립트로 하여금 정보에 접근하는 방법을 제공하기 위함. 이러한 정보는 한 환경에서 또 다른 환경에서 각기 다를 수 있음.
- 예를 들어, 파일의 위치나 디렉토리의 위치는 컴퓨터마다 다르거나, 운영체제마다 다를 수 있음. 환경 변수를 사용함으로써 프로그램은 이러한 정보에 접근할 수 있음. 그것이 실행되고 있는 환경의 구체적인 세부사항에 대해 알 필요 없이. 이는 프로그램을 더 유지보수 하기 쉽게 만들고, 더 사용하기 편하게 만듦.(=portable)
- 환경 변수를 사용하는 또 다른 이유; 프로그램 자체를 수정하지 않고 프로그램이나 스크립트의 행동behavior을 커스터마이징 할 수 있는 방법을 제공함. 예를 들어, 유저는 프로그램마다 그것의 디폴트 데이터 디렉토리를 다르게 설정하고 싶을 수 있음.
11.6 종합 설계: 소형 웹 서버The Tiny Web Server
- TINY 웹 서버 소개
- 프로세스 제어, Unix I/O, 소켓 인터페이스, HTTP 등의 개념을 결합
- 웹 브라우저에 정적, 동적 컨텐츠를 모두 제공할 수 있음
- 주요 파일
tiny.c파일- TINY
main루틴- 반복실행 서버로 명령줄에서 넘겨받은 포트로의 연결 요청을 들음
open_listenfd함수를 호출해 듣기 소켓을 오픈- 무한 서버 루프 실행
- 반복적으로 연결 요청 접수
- 트랜잭션 수행
- 자신 쪽의 연결 종단점을 닫음
doit함수- 하나의 HTTP 트랜잭션을 처리함
- 요청 라인을 읽고 분석 (
rio_readlineb함수 이용) - GET 메소드만 지원하므로, 클라이언트가 다른 메소드를 요청할 시
- 에러 메시지
- main 루틴으로 돌아감
- 연결 닫고
- 다음 연결 요청 기다림
- GET 메소드인 경우
- 요청 라인 읽음
- 다른 요청 헤더 무시함
- URI 분석; 파일 이름 + 인자 스트링(query string)
- 요청이 정적 콘텐츠를 위한 것인지, 동적 컨텐츠를 위한 것인지 플래그 설정
- 만일 이 파일이 디스크 상에 없다면 에러 메시지 + 리턴
- 요청이 정적 컨텐츠를 위한 것
- 이 파일이 보통 파일인지, 읽기 권한을 가지고 있는지 검증
- 만일 그렇다면 정적 컨텐츠 제공
- 요청이 동적 콘텐츠를 위한 것
- 이 파일이 보통 파일인지, 읽기 권한을 가지고 있는지 검증
- 만일 그렇다면 동적 컨텐츠 제공
clienterror함수- 일부 오류에 대해서 체크하고 클라이언트에게 보고함
- HTTP 응답을 응답 라인에 적절한 상태 메시지와 함께 클라이언트에게 전송
- 브라우저 사용자에게 에러를 설명하는 응답 body에 HTML 파일도 함께 보냄 (HTML 응답은 body에서 컨텐츠의 크기, 컨텐츠 타입을 나타내야 함.)
- 출력을 위해서는
rio_written함수를 사용
read_requesthdrs함수- TINY는 요청 헤더 내의 어떤 정보도 사용하지 않으며, 이 함수를 호출해서 이들을 읽고 무시함
- 요청 헤더를 종료하는 빈 텍스트 줄:
carriage return과line feed의 쌍
parse_uri함수- 정적 컨텐츠를 위한 홈 디렉토리 = 현재 디렉토리
- 동적 컨텐츠를 위한 실행파일의 홈 디렉토리 =
/cgi-bin - 기본 파일 이름은
./home.html parse_uri함수는 URI를 파일 이름과 옵션으로 CGI 인자 스트링 분석
- 요청이 정적 컨텐츠라면
- CGI 인자 스트링을 지우고
- URI를
./index.html같은 상대 경로로 변환 - 만일 URI가
/문자로 끝나면- 기본 파일 이름 추가
- 요청이 동적 컨텐츠라면
- 모든 CGI 인자 추출
- 나머지 URI 부분을 상대 파일 이름으로 변환
serve_static함수- TINY는 다섯 개의 서로 다른 정적 컨텐츠 타입을 지원: HTML 파일, 무형식 텍스트 파일, GIF, PNG, JPEG로 인코딩된 영상
- local file의 컨텐츠를 포함하는 HTTP 응답 본체를 보내는 함수
- 파일 이름의 접미어 부분을 검사하여 파일 타입 결정
- 클라이언트에 응답 line과 응답 헤더를 보냄 (빈 줄 하나로 헤더를 종료)
- 요청한 파일의 내용을 연결 식별자
fd로 복사해서 응답 본체를 보냄 - read를 위해 filename을 오픈하고 식별자를 얻어옴
Mmap함수로 요청한 파일을 가상메모리 영역으로 매핑 (Mmap을 호출하면 파일 srcfd의 첫 번째 filesize 바이트 주소 srcp에서 시작하는 private read-only 가상 메모리 영역으로 매핑 )- 파일을 메모리로 매핑한 후, 더이상 식별자 필요 없으니 파일 close (메모리 누수 방지)
Rio_written를 이용해srcp에서 시작하는filesize를 클라이언트의 연결 식별자로 복사- 매핑된 가상메모리 주소를 반환 (메모리 누수 방지)
serve_dynamic함수- TINY는 자식 프로세스를
fork하고, 그 후 CGI 프로그램을 자식의 컨텍스트에서 실행하며 모든 종류의 동적 컨텐츠를 제공
- 클라이언트에게
HTTP/1.0 200 OK성공 response 라인 보내기 (CGI 프로그램이 나머지 응답 부분을 보낼 것) - 자식 프로세스는 query_string 환경 변수를 요청온 URI의 CGI 인자로 초기화 (실제 서버는 여기서 다른 CGI 환경 변수들도 마찬가지로 설정하나, 여기서는 생략)
- 자식 프로세스는 자식의 표준 출력(stdout)을 연결 파일 식별자로 재지정
- CGI 프로그램 로드 후 실행 (
Execve)- CGI 프로그램이 자식 컨텍스트에서 실행되므로, execve 함수를 호출하기 전에 존재하던 열린 파일, 환경 변수들에도 동일하기 접근할 수 있음. 그래서 CGI 프로그램이 stdout으로 출력하는 모든 것은 직접 클라이언트 프로세스로 부모 프로세스의 어떤 간섭도 없이 전달 됨.
- 부모는 자식이 종료되어 정리되는 것을 기다리기 위해
wait함수에서 블록
- TINY는 자식 프로세스를
- TINY
adder.c파일- 동적 페이지를 생성하기 위해 돌아갈 CGI 프로그램
- 자식 프로세스에서 돌아감
- 부모가 자식이 생성한 컨텐츠의 종류, 크기를 모르기 때문에 자식 프로세스가
content-type과content-lengthHTTP 응답 헤더, 헤더를 종료하는 빈 줄까지 생성해야 함.
- 실행하기
- 서버 동작시키기
- tiny 디렉토리에서
$ make ./tiny <포트번호>- 예를 들어
./tiny 9999근데 이때 포트번호는 아무거나 상관 없는건가?
- 예를 들어
- 서버 동작
- 웹 →
localhost:9999접속 - 고질라가 보이면 정상 접속 확인
- tiny 디렉토리에서
- adder 프로그램 실행하기
- 웹 →
localhost:9999/cgi-bin/adder?인자1&인자2접속- 예를 들어
localhost:9999/cgi-bin/adder?15000&213
- 예를 들어
- 웹 페이지에 더한 값이 표시되면 성공
- 웹 →
- 서버 동작시키기
11.7 summary
[Client Server Architecture – Detailed Explanation]https://www.interviewbit.com/blog/client-server-architecture/ ↩︎
Differences between a switch and a bridge | CCNA# (geek-university.com) ↩︎
[Client Server Architecture – Detailed Explanation]https://www.interviewbit.com/blog/client-server-architecture/ ↩︎
Caching static and dynamic content | How does it work? | Cloudflare ↩︎
[IT 엔지니어의 소박한 개인 지식 박물관]https://withbundo.blogspot.com/2016/04/http-3-getpost.html ↩︎
'컴퓨터 시스템' 카테고리의 다른 글
| 컴퓨터 시스템 정리 (CSAPP) Chapter 9 가상메모리 (0) | 2022.12.03 |
|---|---|
| 컴퓨터 시스템 정리 (CSAPP) Chapter 6 (0) | 2022.12.03 |
| 컴퓨터 시스템 정리 (CSAPP) Chapter 3 Machine-Level Reperesentation of Programs (0) | 2022.11.30 |
| 컴퓨터 시스템 정리 (CSAPP) Chapter 1 A tour of Computer Systems (1) | 2022.11.09 |