- 개인적으로 공부하면서 지속적으로 정보를 추가, 수정, 삭제합니다.
- 정확하지 않은 부분 피드백 주시면 감사합니다.
- 본 포스팅은 컴퓨터 시스템 (줄여서 CSAPP) 교재를 강의와 함께 노트한 것입니다.
- 노란색 하이라이트는 블로그 주인의 생각 + 개인적으로 이해가 더 필요한 부분을 표시한 것입니다. 특별히 더 중요한 개념으로 표시한 것이 아닙니다.
참고: Computer System A Programmers Perspective (3rd), Randal E. Bryan, David R. O’Hallaron, 김형신 번역, 피어슨에듀케이션코리아, 2016
9장의 학습 목표
- 가상메모리 시스템의 작동 방식과 특정을 이해하기
- 서로 다르면서, 동시에 실행되는 프로세스들이 어떻게 각각 동일한 주소 범위를 이용할 수 있는지 이해하기
- 일부 페이지들을 공유 하면서 어떻게 개별적인 페이지 사본들을 가질 수 있는지 이해하기
- 가상메모리를 관리하고 조작하는 작업과 관련된 이슈 이해하기
- 표준 라이브러리 함수인 malloc과 free 연산과 같은 저장 장치 할당기들에서의 연산 이해하기
이러한 내용을 다루는 이유
- 가상메모리 공간은 단지 프로그램이 분할해서 서로 다른 저장 단위로 만들어주는 배열에 불과하다는 개념을 강조
- 저장 장치 누수 & 잘못된 포인터 참조와 같은 메모리 참조 에러를 포함하는 프로그램에서의 효과를 이해하는 데 도움
- 응용 프로그래머들은 애플리케이션의 필요와 특성에 최적화된 자신만의 저장장치 할당기(storage allocators)를 개발할 수 있음
- 컴퓨터 시스템에서 하드웨어와 소프트웨어 모두를 통합된 방식으로 다루면 얻을 수 있는 장점을 알 수 있음
intro
- 프로세스들은 CPU와 메인 메모리를 다른 프로세스들과 공유해야만 함
- 프로세스끼리 메모리를 공유하며 발생하는 문제점
- CPU에 대한 요구가 증가하며 프로세스들이 점점 느려짐 → 너무 많은 프로세스가 너무 많은 메모리를 요구하면 이들 중 일부는 실행할 수 없게 됨
- 메모리는 손실에 취약함 → 일부 프로세스가 다른 프로세스가 사용하는 메모리에 쓰기 접근을 하면 다른 프로세스가 제대로 동작 못 함
- ∵ 메모리를 더 효율적으로 사용하고, 더 적은 에러를 갖게끔 도와줄 시스템이 필요함
- 가상 메모리 VM, virtual memory
- 컴퓨터 시스템의 위대한 아이디어 중 하나!
- 메인 메모리의 추상화
- 메인 메모리를 더 효율적으로 사용하고, 적은 에러를 갖게끔 도와줌
- 각 프로세스에 하나의 크고, 통합된, 사적 주소공간을 제공
- 가상 메모리가 제공하는 중요한 기능 세 가지
- 메인 메모리를 디스크에 저장된 주소공간(address space)에 대한 캐시로 취급함으로써 효율적으로 메인 메모리를 사용 → 메인 메모리 내 활성화 영역만 유지하고, 필요에 따라 디스크와 메모리 간 데이터를 전송 (물리 메모리에 대한 의존성↓)
- 각 프로세스에 통일된 주소 공간을 제공함으로써 메모리 관리를 단순화
- 각 프로세스의 주소공간을 다른 프로세스에 의한 손상으로부터 보호
- 프로그래머가 가상 메모리를 이해해야 하는 이유
- 가상메모리가 중심이다.
- 가상메모리는 모든 컴퓨터 시스템 레벨에 스며들어 있다.
- 가상메모리는 강력하다.
- 애플리케이션으로 하여금 메모리 블록을 만들고 없애고,
- 디스크 파일에 메모리 블럭을 맵핑하고,
- 다른 프로세스와 메모리를 공유할 수 있게 한다.
- 가상메모리는 위험하다. 포인터가 주는 권력…
- 애플리케이션은 변수를 참조하고, 포인터를 역참조하고,
malloc같은 동적 할당 패키지로 호출할 때마다 가상메모리와 상호작용한다. - 가상메모리가 잘못 되면, 애플리케이션은 메모리 관련 버그를 겪을 것이다.
- 애플리케이션은 변수를 참조하고, 포인터를 역참조하고,
- 가상메모리가 중심이다.
학습목표
- 어떻게 가상메모리가 작동하는지 이해하기
- 어떻게 가상메모리가 사용되고, 애플리케이션에 의해서 관리되는지 이해하기
- 명시적 메모리 매핑 이해하기
malloc과 같은 동적 메모리 할당기를 통해 가상메모리를 관리하는 법 이해하기- 메모리 관련 에러들의 원인과 해결책 이해하기
9.1 물리 및 가상주소 방식(Physical And Virtual Addressing)
추가) 절대주소와 상대주소

- 프로그램은 절대주소, 상대주소를 사용할 수 있음
- 절대주소: 메모리 장치 고유의 주소. 고수준 프로그래밍 언어에서 포인터 데이터 형으로 알려져 있음.
- 상대주소: 기준이 되는 주소(base address)를 두고 그로부터 얼마나 떨어져 있는지(=offset, distance) 표기하는 주소

- 베이스 레지스터: 실행 중인 프로그램의 가장 작은 물리 주소를 저장
- 경계 레지스터(한계 레지스터, limit register): 논리 주소의 최대 크기를 저장 → 다른 프로그램의 영역을 침범할 수 있는 명령어의 실행을 막음
- 위 그림에서 운영체제 영역부터 0으로 계산하면 절대 주소
- 사용자 영역부터 0으로 계산하면(즉, 기준 주소를 두고 위치 계산) 40이라고 부르게 됨 → 이게 상대 주소, 논리 주소 공간(logical ≒ virtual)
물리 주소 방식 (physical addressing)

- 초기의 PC들이 사용한 방식(여전히 계속 쓰고 있는 시스템도 있음)
- 메인 메모리는 연속적인 바이트 크기 셀의 배열로 구성 됨
- 메인 메모리의 각 바이트는 고유의 물리 주소(PA, physical address)\를 가짐(e.g.: 첫 번째 바이트는 주소 0, 다음 바이트는 주소 1 … )
- 물리 주소를 사용하여 CPU가 메모리에 접근하는 방법
- CPU의 LOAD 명령(데이터 읽기) 실행
- CPU는 유효 물리 주소(effective physical address)를 생성
- 유효 물리 주소를 메모리 버스를 통해 메인 메모리에 전달
- 메인 메모리는 해당 주소부터 데이터를 읽어 나감
- 메인 메모리는 읽은 데이터를 CPU에게 돌려줌
- CPU는 그것을 레지스터에 저장
가상 주소 방식 (virtual addressing)

- 현대의 프로세스들이 사용하는 방식
- 가상 주소를 사용하여 CPU가 메모리에 접근하는 방법
- CPU는 가상 주소(VA, virtual address) 를 생성
- 주소 번역(address translation): 메인 메모리에 보내기 전에 가상 주소를 적절한 물리 주소로 바꿈. 이 과정에서 CPU와 운영체제 간의 긴밀한 협력 필요.
- CPU 칩 내의 메모리 관리 유닛(MMU, memory management unit)이라는 하드웨어가 메인 메모리에 저장된 참조 테이블을 사용하여, 런타임에 가상 주소를 번역함
- 이 참조 테이블의 내용은 운영체제가 관리 함
- 이후는 물리 주소 방식대로 메인 메모리에 접근
9.2 주소 공간(Address Spaces)
주소 공간이란?
- 음수가 아닌 정수 주소의 정렬된 집합; e.g.: {0, 1, 2, … }
선형 주소 공간(linear address space)
- 주소 공간의 정수가 연속적인 경우
- 이 책에서는 언제나 선형 주소 공간을 가정함
가상 주소 공간(virtual address space)
- CPU는 가상 주소공간이라고 불리는
주소의 주소공간에서 가상의 주소를 생성 정확한 정의가 필요함 ; e.g.: {0, 1, 2, … N-1}
물리 주소 공간
- M바이트의 물리 메모리에 대응되는 물리 주소; e.g.: {0, 1, 2, … M-1}
- M은 항상 2의 제곱일 필요는 없음
주소 공간의 크기
- 가장 큰 주소를 표시하는데 필요한 비트 수
주소를 갖는 가상 주소공간은 n-비트 주소공간이라고 부름 - 현대 시스템은 32비트, 또는 64비트의 가상 주소공간을 지원함
주소공간의 중요성 여기 다시 정확히 이해
- 데이터 객체(bytes)와 그것들의 특성(addresses) 사이의 구분을 명확하게 해줌
- 각각의 데이터 객체가 여러 독립적인 주소(multiple independent addresses)를 가질 수 있게 함
- 이 각각의 주소는 서로 다른 주소공간에서 선택되었다
- 메인 메모리의 각 바이트는 가상 주소공간으로부터 선택된 가상주소를 가진다
9.3 캐싱 도구로서의 VM
intro
- 가상메모리는 디스크에 저장된 N개의 바이트 크기의 셀의 배열
- 각각의 바이트는 고유한 가상 주소를 가짐, 그리고 그것은 그 배열(가상 메모리)의 인덱스로 기능함
- 가상 메모리의 담긴 내용들은 메인 메모리에 캐시 됨
- 디스크의 데이터들은 블럭으로 쪼개지고, 그 블럭은 디스크와 메인 메모리 사이의 전송 유닛(transfer unit)으로 기능함 ⇒ 가상 메모리 시스템은 가상 메모리를 고정된 크기의 블럭(=가상 페이지VP, virtual pages)으로 쪼갬
- 각각의 가상 페이지는
바이트의 크기를 가짐 - 이와 비슷하게 물리 메모리는 물리 페이지(PP, physical pages, page frames) 로 쪼개지며, P 바이트를 가짐
- 가상 페이지는 세 개의 서로 겹치지 않는 세 개의 집합으로 나뉨:

- Unallocated: VM 시스템에 의해서 아직 할당되지 않은(생성되지 않은) 페이지들. unallocated blocks는 어떠한 관련된 데이터도 가지고 있지 않음. 그러므로 디스크에서 공간을 차지하지 않음
- Cached: 할당된 페이지들. 현재 물리 메모리에 캐쉬된 상태.
- Uncached: 할당된 페이지들. 하지만 물리 메모리에 캐쉬되지 않은 상태.
9.3.1 DRAM(Dynamic Random Access Memory) 캐시의 구성
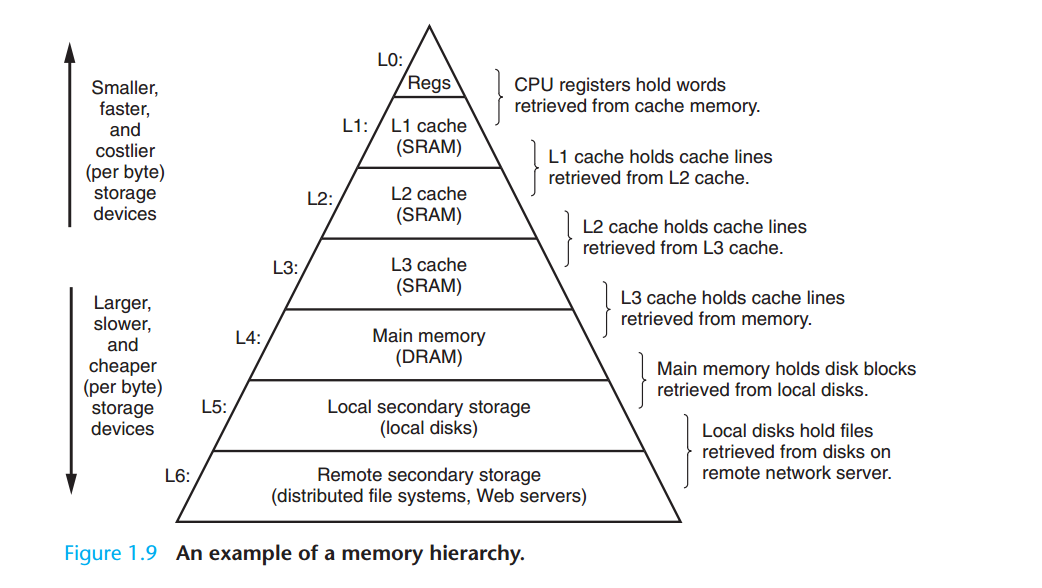
DRAM과 SRAM(Static Random Access Memory)
- SRAM 캐시: CPU와 메인 메모리 사이의 L1, L2, L3 캐시 메모리
- DRAM 캐시: 가상 메모리 시스템의 캐시. 메인 메모리의 가상 페이지를 캐시함.
DRAM 캐싱시 발생할 수 있는 비용
- 큰 규모의 미스 비용
- 메모리 계층 내에서 DRAM의 위치를 고려했을때, SRAM보다 최소 10배 느리고 디스크는 DRAM보다 100000배 느림.
- 따라서 DRAM 캐시 미스는 SRAM의 캐시 미스에 비하여 비용이 큼
- 첫 번째 바이트를 접근하는데 드는 비용
- 디스크 섹터로부터 첫 번째 바이트를 읽는 비용이 연속적인 바이트를 읽는 것보다 약 100,000배 더 느림
비용을 줄이기 위한 DRAM 캐시 구성
- 가상 페이지가 점점 커짐 (4 KB to 2 MB)
- 큰 미스 비용때문에 DRAM 캐시는 fully associative → 즉 어떠한 가상 페이지도 어떠한 물리 페이지 안에 위치될 수 있음
- fully associative?
- 어떠한 메모리 주소든 캐시 내의 어떠한 위치에 저장될 수 있다는 뜻.
- 데이터가 각기 다른 위치에 저장되게끔 함으로써, 프로세서는 빠르고 효율적으로 데이터에 접근할 수 있음. 게다가, 이는 또한 프로세서의 노력을 덜어주는데 똑같은 주소를 계속 찾을 필요가 없기 때문. 프로세서가 특정 주소를 찾기 위해 전체 캐시를 검색할 필요가 없기 때문.
- fully associative?
- SRAM에 비해 매우 복잡한 DRAM 캐시 교체 알고리즘 → 잘못된 가상 페이지를 교체하면 비용이 매우 높기 때문.
- 디스크의 큰 접근 시간 → DRAM은 write-through 대신에 write-back을 사용
- Write-Through은 데이터를 쓰기 전에 메모리와 디스크 사이에 디스크에 데이터가 쓰여지는 것. 이는 데이터를 저장하기 전에 메모리 내의 캐시 메모리를 거쳐 디스크로 저장하는 것을 말합니다.
- Write-Back은 데이터를 쓰기 전에 메모리로 먼저 쓰여진 후, 디스크에 쓰여지는 것. 이는 데이터를 저장하기 전에 메모리 내의 캐시 메모리에 저장하고 디스크에는 저장하지 않는 것을 말합니다.
- 결론적으로 Write-Back이 더 빠르다. 메모리 내의 캐시 메모리에 데이터를 저장하고 디스크는 저장하지 않기 때문에 읽기/쓰기 속도가 향상되고 디스크의 작업량이 줄어들기 때문입니다.
추가 내용
- SRAM과 DRAM의 차이
DRAM과 SRAM은 두 가지 다른 유형의 메모리 입니다. 가장 큰 차이점은 DRAM이 데이터를 저장하기 위해 저항과 커패시터를 사용하는 반면, SRAM은 트랜지스터를 사용하기 때문에 SRAM이 더 빠르고 정확한 특징이 있습니다. 또한 DRAM은 전원이 꺼지면 데이터가 손실되는 동적 메모리이기 때문에 전원이 꺼지면 메모리에 저장된 데이터가 손실되는 경우가 있습니다. 반면 SRAM은 정적 메모리이기 때문에 전원이 꺼지더라도 메모리에 저장된 데이터는 유지됩니다. 또한 DRAM이 더 저렴하고 메모리 용량이 더 많은 특징이 있습니다.
- 메인 메모리와 DRAM의 차이
메인 메모리와 DRAM은 컴퓨터에서 매우 중요한 부품이지만, 서로 다른 개념을 가지고 있습니다. 메인 메모리는 컴퓨터에 설치된 모든 메모리의 총합을 말하며, 이는 컴퓨터의 운영 체제와 실행 중인 프로그램의 데이터를 임시로 저장하는 역할을 합니다. 메인 메모리는 컴퓨터의 CPU가 데이터를 읽고 쓰는데 기본적으로 필요한 메모리 장치입니다. 반면 DRAM은 메인 메모리의 한 종류로, 컴퓨터의 메인 메모리 중 일부를 차지하고 있습니다. DRAM은 컴퓨터의 메인 보드에 위치한 메모리 슬롯에 삽입되어 있으며, 이를 통해 CPU가 데이터를 읽고 쓸 수 있도록 합니다. 일반적으로 컴퓨터의 메인 메모리는 다양한 종류의 메모리가 섞여 있으며, DRAM은 이 중 하나입니다.
- 메인 메모리 & SRAM, DRAM
메인 메모리와 DRAM은 컴퓨터에서 매우 중요한 부품이지만, 서로 다른 개념을 가지고 있습니다. 메인 메모리는 컴퓨터에 설치된 모든 메모리의 총합을 말하며, 이는 컴퓨터의 운영 체제와 실행 중인 프로그램의 데이터를 임시로 저장하는 역할을 합니다. 메인 메모리는 컴퓨터의 CPU가 데이터를 읽고 쓰는데 기본적으로 필요한 메모리 장치입니다. 반면 DRAM은 메인 메모리의 한 종류로, 컴퓨터의 메인 메모리 중 일부를 차지하고 있습니다. DRAM은 컴퓨터의 메인 보드에 위치한 메모리 슬롯에 삽입되어 있으며, 이를 통해 CPU가 데이터를 읽고 쓸 수 있도록 합니다. 일반적으로 컴퓨터의 메인 메모리는 다양한 종류의 메모리가 섞여 있으며, DRAM은 이 중 하나입니다.
9.3.2 페이지 테이블
1. 페이지 테이블의 등장
- 모든 캐시는 데이터가 어디에 캐시되어있는지 알 수 있는 방법이 필요
- 즉, VM 시스템은 가상 페이지가 DRAM 어디에 캐시되었는지 알아야 함. 어떤 물리 페이지가 캐싱되었는지 알아야 함.
- 미스가 존재한다면, 시스템은 디스크 어디에 가상 페이지가 저장되어 있는지 결정해야 하며, 물리 메모리 중에서 희생자 페이지(victim page)를 선택해야 하고, 가상 페이지를 디스크에서 DRAM으로 복사해 희생자 페이지를 교체함
- ※ 캐시 미스란?
- 컴퓨터가 메인 메모리에 저장되지 않은 데이터를 읽거나 쓸 때 발생하는 문제.
- 가상 메모리 시스템에서 캐시 미스는 가상 메모리 시스템으로부터 발생한 데이터 요청을 캐시 안에서 찾을 수 없을때 발생함
- 이는 캐시 안에 주소가 없거나, 같은 주소에 대해 두 개 이상의 요청 사이의 충돌이 있거나 할 때 발생
- 그러한 경우에, 미스 해결을 위한 요청이 메인 메모리로 보내져야 하고, 이는 상당한 성능 저하를 일으킬 수 있음.
- ※ 캐시 미스란?
2. 페이지 테이블

- 운영체제 소프트웨어, MMU 내의 주소 번역 하드웨어, 페이지 테이블이 윗 항목에서 말한 내용들을 수행해줌.
- 페이지 테이블이란?:
- 물리 메모리에 저장된 자료구조
- 가상 페이지를 물리 페이지로 mapping 해줌.
- 페이지 테이블은 페이지 테이블 엔트리(PTE, page table entry)\의 배열
- 주소 번역 하드웨어는 이들이 가상주소를 물리 주소로 변환할 때마다 페이지 테이블을 읽음.
- 운영체제는 페이지 테이블의 콘텐츠 관리와 페이지들을 디스크와 DRAM 사이에서 왔다 갔다 하는 것을 관장함.
- 가상 주소 공간의 각 페이지는 페이지 테이블 내에 고정된 오프셋 위치에 PTE를 갖게 됨
3. 페이지 테이블 엔트리(PTE)
- 한 개의 유효비트(valid): 가상페이지가 현재 DRAM에 캐시되어 있는지 아닌지를 나타냄
- 유효비트가 1인 경우
- = Cached
- 주소 필드 → 가상페이지가 캐시되어 대응되는 DRAM의 물리 페이지의 시작을 나타냄
- 유효비트가 0인 경우
- 주소 필드가 Null → Unallocated
- 가상페이지가 아직 할당되지 않았음
- Null이 아닌 경우 → Allocated
- 주소 필드 → 디스크 상의 가상페이지의 시작 부분을 가리킴
- 주소 필드가 Null → Unallocated
- 유효비트가 1인 경우
- n비트의 주소 필드: Null, 물리 페이지 번호, 가상 페이지 주소를 나타냄
9.3.3 페이지 적중Page Hits
1. 페이지 적중이란?
- CPU가 DRAM에 캐시되어 있는 가상메모리의 워드 읽기에 성공한 것
2. 페이지 적중 과정
- 주소 번역 하드웨어가 해당 워드의 PTE를 찾아내기 위해 가상 주소를 인덱스로 사용하고, 메모리부터 그것을 읽어냄
- 주소 번역 하드웨어는 유효비트를 확인하여, 찾고자 하는 워드가 캐시 되어있는지 아닌지 알 수 있음
- PTE 내의 물리 메모리 주소를 사용하여 해당 워드의 물리 주소를 구성
9.3.4 페이지 오류Page Fault
1. 페이지 오류란?
- DRAM 캐시 미스; CPU가 DRAM에 캐시되어 있지 않은 워드를 참조하는 것
- 대체적으로 어떤 프로그램에서 “페이지 폴트”가 발생했다고 할 때 의미하는 바는, 운영체제가 디스크로 스왑 아웃한 가상 주소 공간의 한 부분을 접근한 것
2. 페이지 오류 과정
- CPU가 DRAM에 캐시되어 있지 않은 워드를 참조
- 주소 번역 하드웨어는 메모리에서 PTE를 읽으면서, 해당 데이터가 캐시되어 있지 않다는 것을 유효비트로부터 알아냄
- 페이지 오류 예외를 일으킴
- 페이지 오류 예외 → 커널 내의 페이지 오류 예외 핸들러 호출
- 희생자 페이지를 선택
- 커널은 희생자 페이지에 대한 PTE를 수정하여 유효 비트와 주소 필드 업데이트 (더이상 캐시되지 않았음을 갱신)
- 커널은 디스크로부터 메모리로 원래 접근하고자 했던 워드 내 데이터를 복사
- PTE 갱신 후 리턴
- 페이지 오류 핸들러가 오류 인스트럭션 재시작
- 오류 가상 주소를 주소 번역 하드웨어로 재전송
- 이번에는 제대로 캐시되었으므로 페이지 적중으로 처리 됨
- 가상메모리 용어
- 블록 = 페이지
- 스와핑swapping, 페이징paging: 디스크와 메모리 사이에 페이지를 전송하는 것. 페이지는 디스크에서 DRAM으로 스와핑해 들어오며(swapped in, paged in), DRAM에서 디스크로 스와핑되어 나간다(swapped out, paged out).
- 요구 페이징demand paging: 캐시 미스가 발생했을 때, 페이지가 스왑되어 들어올 때까지 기다리는 것(그런 전략)
9.3.5 페이지의 할당
#todo-그림9쩜8
페이지 할당 과정
- 운영체제가 가상메모리의 새로운 페이지를 할당(e.g.:
malloc호출) - 가상 메모리에 페이지가 할당됨
- PTE가 새롭게 만든 페이지를 가리키도록 할당 됨
9.3.6 문제해결을 위한 또 한 번의 지역성의 등장Locality To the Rescue Again
1. 메모리에서 지역성이란?
- 프로그램이 수행되는 동안 접근하는 데이터 및 중요 코드의 물리적 배치 상 관계
- 속도를 높이기 위한 캐시 이용이나 메모리 공간을 절약하기 위해 사용됨. 메모리 주소가 연속되는 것이 지역성의 가장 좋은 예이며, 캐시는 가장 최근에 사용된 메모리 주소를 저장함.
- 지역성은 프로그램 성능을 향상시킨다. 왜?
- 같은 영역 또는 주변 영역에 자주 접근되는 데이터들은 메모리에 이미 적재되어 있어서 반복 접근이 가능하므로로
- e.g.: 자바로 구현된 프로그램이 있다. 이 프로그램은 선형 검색을 사용하여 배열 내의 데이터를 찾는 기능을 수행한다. 만약 배열 내의 데이터가 물리적으로 연속적으로 나열되어 있다면, 이 프로그램은 중간에 항목을 놓칠 가능성이 훨씬 낮아진다. 이는 인접한 데이터가 같은 페이지 내에 저장되어 있기 때문에 이 데이터를 찾기 위해 한번의 접근만 하면 되기 때문이다. 따라서 배열 내의 데이터가 연속적으로 나열되어 있다면, 프로그램의 성능이 크게 향상될 것이다.
2. 가상메모리의 지역성locality
- 지역성 덕분에 가상 메모리는 성능이 떨어지지 않고 잘 작동함
- 동적 집합working set, 거주 집합resident set : active pages의 작은 집합. 프로그램이 전체 실행 중에 참조하는 페이지의 수가 물리 메모리의 사이즈를 초과할 수도 있음에도 불구하고, 지역성의 원리는 어느 시점에서건 동적 집합으로 동작하도록 해줌.
- working set이 메모리로 페이지되는 초기의 overhead 이후에, working set을 연속적으로 참조하는 것은 추가적인 디스크 트래픽 없이 페이지 적중page hit을 달성할 수 있게 됨.
3. 쓰래싱thrashing
- 동적 집합의 크기가 물리 메모리 크기를 초과하는 경우에 발생하는 현상
- 페이지가 계속 스왑되어 들어오고 스왑되어 나감
- 결국 성능 저하를 일으킴
9.4 메모리 관리를 위한 도구로서의 VM

다수의 가상 주소공간
- 운영체제는 각 프로세스마다 별도의 페이지 테이블을 제공 → 별도의 가상 주소공간을 제공함!
- 이때 여러 가상 페이지들이 동일하게 공유된 물리페이지에 매핑될 수 있음 (그림 9.9의 PP 7의 경우)
요구 페이징 + 분리된 가상주소 공간을 통한 가상 메모리의 메모리 관리
- 링킹의 단순화
- 주소공간은 각 프로세스에서 사용하는 코드와 데이터가 실제로 물리 메모리 어디에 위치하는지와 상관 없이 동일한 기본 포맷을 사용하게 함(e.g.: 코드 구역, 그 위에 데이터 구역, 스택은 최상위 부분에서 아래로 …)
- 이러한 통일성으로 링킹이 단순화됨
- 로딩을 단순화
- 실행파일과 공유 목적파일을 메모리에 쉽게 로드하게 해줌
- 로더는 코드와 데이터 세그먼트를 위한 가상의 페이지를 할당 → 캐시되지 않은 상태로 표시 → PTE가 목적파일의 위치를 가리키게 함 (디스크로부터 메모리로 데이터를 복사하지 않은 채로)
- 메모리 매핑memory mapping : 연속된 가상페이지를 임의의 파일의 임의의 위치로 매핑하는 것. ??? 리눅스 운영체제는
mmap이라는 시스템 콜을 제공하며, 이는 메모리 매핑을 해줌
- 공유를 단순화
- 별도의 주소공간은 운영체제로 하여금 사용자 프로세스와 운영체제 자신 사이에서 공유를 관리하는 일관된 메커니즘을 제공함
- 각 프로세스는 다른 프로세스와 공유되지 않는 자신만의 사적인 코드, 데이터, 힙, 스택 영역을 가짐. 이 경우 운영체제는 대응되는 가상페이지를 중첩되지 않는 물리페이지로 매핑하는 페이지 테이블을 만듦
- 코드, 데이터 공유가 바람직한 경우도 있음
- 모든 프로세스는 동일한 운영체제 커널 코드를 호출함
- 모든 C 프로그램은 표준 C 라이브러리 루틴 호출함
- 이를 각 프로세스에 별도로 포함시키기 보다는, 서로 다른 프로세스에 들어있는 가상페이지를 동일한 물리페이지로 매핑하여 한개의 사본을 공유하도록 함 (그림 9.9의 shared page)
- 메모리 할당을 단순화
- 가상메모리는 추가적인 메모리를 사용자 프로세스에 할당할 때 간단한 메커니즘을 제공함
- 사용자 프로세스로 돌고 있는 프로그램이 추가적인 힙 공간을 요청(e.g.:
malloc호출) → 운영체제는 적당한 수 k 만큼의 가상 페이지를 할당함 → 이 가상메모리 페이지들을 물리 메모리 내에 위치한 k개의 임의의 물리페이지로 매핑함 → 페이지들은 물리 메모리 내에 랜덤하게 흩어져 있으며, 운영체제는 페이지 테이블 덕분에 물리 메모리에서 k개의 연속적인 페이지를 찾을 필요가 없음
9.5 메모리 보호를 위한 도구로서의 VM
메모리 접근 제어
- 운영체제는 메모리 시스템에 접근하는 것을 제어할 수 있음
- 메모리 접근의 제한사항
- 사용자 프로세스는 자신의 읽기-허용 코드 섹션을 수정하면 안 됨
- 커널 내의 코드와 데이터 구조들도 읽거나 수정할 수 없어야 함
- 프로세스 간 통신시스템 콜을 호출해서 허용되지 않았다면, 다른 프로세스의 사적 메모리를 읽거나 쓸 수 없어야 함.

페이지 수준에서 메모리 보호하기
- 각 프로세스의 PTE의 존재하는 세 개의 허가 비트
- SUP: 프로세스들이 이 페이지에 접근하기 위해 커널 모드(수퍼바이저)로 돌고 있어야 하는지를 나타냄. 커널 모드로 돌고 있는 프로세스들은 모든 페이지에 접근하도록 허용되지만, 사용자 모드에서 돌고 있는 프로세스는 SUP가 0인 페이지들만 접근이 허용 됨
- READ: 이 페이지에 대한 읽기 접근
- WRITE: 이 페이지에 대한 쓰기 접근
- 어떤 명령어가 허가사항을 위반하는 경우?
- CPU는 일반 보호 오류를 발생
- 커널 내에 있는 예외 핸들러로 제어를 전달함.
- 예외 핸들러는 위반한 프로세스로 SIGSEGV(Segmentation Violation Signal) 시그널을 보냄 → “segmentation fault”
(※ Segmentation은 컴퓨터 시스템에서 메모리의 논리적 단위를 구분하는 것이다. 여기서 논리적 단위란 프로그램의 구성 요소를 구별하고 메모리 영역을 효율적으로 관리하기 위해 프로그램을 논리적으로 나누는 것을 의미한다. SIGSEGV는 실행 중인 프로그램이 올바르게 메모리를 참조하지 못하거나 잘못된 메모리 주소를 가리킬 때 발생)
9.6 주소의 번역

학습목표
- 가상메모리를 지원하기 위한 하드웨어의 기능을 이해하기
페이지 테이블을 사용한 주소의 번역

페이지 적중과 페이지 오류에 대한 동작 모습

9.6.1 캐시와 VM의 통합

- 물리 주소를 사용하는 캐시와 가상메모리의 통합
- SRAM 캐시에 접근하기 위해서는 대부분 물리 주소지정을 선택함
- 주소 번역이 캐시 참조 이전에 일어남
- PTE가 다른 데이터 워드와 마찬가지로 캐싱될 수 있음
9.6.2 TLB를 사용한 주소 번역 속도의 개선

TLB(translation lookaside buffer) 캐시의 등장
- CPU가 가상주소를 생성할 때마다 MMU는 이를 물리주소로 번역하기 위해 PTE를 참조함
- → 페이지 폴트 등 최악의 경우 또 메모리에서 불러오기 작업을 해야하며, 이를 위한 비용이 많이 듦
- → PTE를 L1에 캐싱함으로써 이 비용을 줄일 수 있음
- → MMU내에 TLB라는 작은 캐시를 또 포함함으로써 비용을 더 줄일 수 있음
TLB란?
- 작은 가상주소지정 캐시
- 각 라인은 하나의 PTE로 구성된 하나의 블록을 저장
- 모든 주소 번역 단계가 CPU 칩 내의 MMU 안에서 수행되기 때문에 매우 빠름
9.6.3 다중 레벨 페이지 테이블

- 하나의 페이지 테이블만을 사용할 경우, 애플리케이션이 가상 주소 공간의 작은 부분만 참조한다하더라도 동일한 크기의 페이지 테이블이 메모리에 항상 상주해야 함.
- 페이지 테이블을 압축하는 방법 → 페이지 테이블의 계층구조를 이용함
- 다중 레벨 페이지 테이블의 장점
- 1단계 테이블의 PTE가 null이면 해당 2단계 페이지 테이블이 존재할 필요가 없음 → 메모리 절약 (대부분의 프로그램의 4GB 가상 주소 공간이 미할당 상태이기 때문)
- 1단계 테이블만 메인 메모리에 상주하면 됨. 2단계 테이블은 가상 메모리 시스템에 의해 필요할 때만 만들어지고 페이지 인, 페이지 아웃되며, 이는 메인 메모리의 부담을 줄여줌. 가장 많이 사용되는 레벨 2 페이지 테이블만 메인 메모리 안에 캐시되면 됨.
9.6.4 종합 구현: 종단 주소 번역
9.7 사례 연구: 인텔 코어 i7/리눅스 메모리 시스템
9.7.1 코어 i7에서의 주소 번역
9.7.2 리눅스 가상메모리 시스템

9.8 메모리 매핑Memory Mapping
- 메모리 매핑이란?
- 리눅스는 가상메모리 영역(=segment)의 내용을 디스크의 객체object에 연결해서 초기화함
- 가상메모리 영역들은 다음 두 종류의 객체 중 하나로 매핑됨 좀 더 이해 필요
- 리눅스 파일 시스템 내의 일반 파일(regular file)
- 일반적인 파일(e.g. 실행 파일)을 페이지 단위로 쪼갠 것이 가상메모리 영역에 매핑될 수 있음
- 각각의 페이지 단위 조각에는 가상 페이지의 초기 내용(initial contents)이 담김 ?
- demand paging 때문에, CPU가 페이지에 접근(i.e. 페이지의 주소공간의 영역 내에 들어가는 가상주소를 만들어내는 것) 하기 전까지는 이러한 가상 페이지 중 어떤 것도 실제로 물리 메모리에 스왑인 되지 않음.
- 영역이 파일 섹션보다 더 크다면, 남은 부분은 0으로 채워짐
- 무기명 파일(Anonymous file)
- 무기명 파일은 커널이 만든 것으로, 모두 이진수 0을 포함
- CPU가 이 영역의 가상페이지에 처음 접근할 때:
- 커널은 물리 메모리에서 적당한 victim page(희생자 페이지)를 찾아내고,
- 이 희생자 페이지가 dirty 하다면 스왑 아웃하고,
- 희생자 페이지를 0으로 덮어 쓰고,
- 이 페이지가 존재한다고 표시하기 위해 페이지 테이블을 갱신
- 이 과정에서 디스크와 메모리 사이에 어떤 데이터도 오가지 않음 → 이 때문에 무기명 파일로 매핑된 영역 내의 페이지는 무요구(demand-zero) 페이지라고도 불림
- 리눅스 파일 시스템 내의 일반 파일(regular file)
Demand-zero memory area는 컴퓨터 메모리 중 하나로, 메모리가 필요할 때만 수동으로 로드되는 메모리 영역을 말합니다. 이 영역은 시스템이 정상적으로 동작하기 위해 필요한 프로그램 코드나 데이터를 미리 메모리에 로드하지 않고, 필요할 때 메모리 로드를 요청하는 절차를 사용합니다.
9.8.1 다시 보는 공유 객체
1. 프로세스간 객체 공유
- 많은 프로세스는 동일한 읽기 전용 코드를 가지고 있으며, 많은 프로그램은 동일한 읽기 전용 런타임 라이브러리 코드에 접근해야 함
- → 물리 메모리 상에 공통으로 사용하는 코드를 중복해서 두는 것은 낭비!
- → 메모리 매핑으로 객체들을 다수의 프로세스와 공유하게 함
2. 가상메모리로의 객체의 매핑
- 객체는 공유 가상메모리 영역으로 공유 객체 또는 사적 객체로 매핑된다.
- 공유 객체shared object
- 만약 한 프로세스가 공유 객체를 자신의 공유 주소공간으로 매핑한다면, 이 프로세스가 이 영역에 쓰는 모든 내용은 자신의 공유 메모리 내로 객체를 매핑한 다른 프로세스들도 볼 수 있음
- 이러한 변경은 디스크 상의 원래의 객체에도 반영 됨
- 공유 객체가 매핑된 가상메모리 영역은 공유 영역shared area라고 불림
- 사적 객체private object
- 사적 객체에 매핑된 영역에 가한 수정사항은 다른 프로세스들이 볼 수 없음
- 이 영역에서 프로세스가 수행한 모든 쓰기 작업은 디스크 상의 객체에 반영되지 않음
- 사 객체가 매핑된 가상메모리 영역은 사적 영역private area라고 불림
9.8.2 다시 보는 fork함수
1. fork 함수?
- fork 함수는 운영체제 내부에서 사용하는 함수
- 현재 프로세스를 복제하여 새로운 프로세스인 자식 프로세스를 생성함
- 복제된 프로세스는 부모 프로세스와 동일한 주소 공간을 공유하고, 부모 프로세스가 종료되면 자동으로 자식 프로세스도 종료됨
2. fork 함수와 메모리 매핑
- 현재 프로세스의 fork 함수 호출
- 커널은 새로운 자식 프로세스를 위한 가상메모리를 생성, 고유한 PID(process ID)를 부여
- 현재 프로세스의 메모리 구조, 영역 구조체, 페이지 테이블과 동일한 사본 생성
- 두 프로세스의 모든 페이지를 read-only로 표시 + 두 프로세스의 영역 구조체를 사적 copy-on-write로 표시
9.8.3 다시 보는 execve 함수
execve 함수
- "execute program"을 뜻함
- 리눅스 환경에서 프로그램을 실행시키기 위한 함수로,
- 주어진 파일의 실행권한이 있는 경우 그 파일을 새로운 프로세스로 실행시킴
- 프로세스의 이름, 명령어 인자를 전달하여 새로운 프로그램 실행 → 현재의 프로그램을 새로운 프로그램으로 대체할 수 있음
9.8.4 함수를 이용한 사용자수준 메모리 매핑
mmap 함수
- 커널에 새 가상메모리 영역을 생성해줄 것을 요청
munmap 함수
- "unmap memory"의 줄임말
- 가상메모리의 특정 영역들을 삭제
- 이후의 삭제된 영역을 참조하는 경우 세그먼트 오류 발생
9.9 동적 메모리 할당
☞ [크래프톤정글 6주차; WIL - 동적 메모리 할당 개발 일지](크래프톤정글 6주차; WIL - 동적 메모리 할당 개발 일지)
intro
mmap,munmap함수를 사용하여 가상 메모리를 생성, 삭제할 수 있음- 하지만 C 개발자들은 추가적인 런타임 가상 메모리를 획득하기 위한 더 편하고 portable한 방법으로 동적 메모리 할당기(dynamic memory allocator) 를 사용함
9.9절의 학습 목표
- 명시적 할당기, 묵시적 할당기의 설계와 구현
- 특히 힙 메모리를 관리하는 할당기를 이해하기
- 하지만 메모리 할당은 다양한 맥락에서 일어나는 일반적인 아이디어임.
- e.g.) 그래프 연산을 많이 하는 애플리케이션은 크기가 큰 블록의 가상메모리를 획득하기 위해 표준 할당기(the standard allocator)를 종종 사용하며, 그래프의 노드들이 만들어지고 없어질 때 그 할당한 블록 내의 메모리를 관리하기 위해 application-specific한 할당기를 사용함.
동적 메모리 할당기(dynamic memory allocator)
- heap이라고 하는 프로세스의 가상메모리 영역을 관리함
- heap: 미초기화된 데이터 영역 직후에 시작해 위쪽으로(높은 주소 방향으로) 커지는 무요구(demand-zero) 메모리 영역
(※ 무요구 메모리 영역: 시스템이 정상적으로 동작하기 위해 필요한 프로그램 코드나 데이터를 미리 메모리에 로드하지 않고, 필요할 때 메모리 로드를 요청)
- heap: 미초기화된 데이터 영역 직후에 시작해 위쪽으로(높은 주소 방향으로) 커지는 무요구(demand-zero) 메모리 영역
- 각각의 프로세스에 대해, 커널은 힙의 꼭대기를 가리키는 변수
brk를 사용함 마치 스택 포인터와 흡사한 - 동적 메모리 할당기는 힙을 다양한 사이즈의 블록block의 모음(collection)으로 유지함
- 블록block: 할당되었거나(allocated), 사용할 수 있는(free) 가상 메모리의 연속적인 덩어리.
- allocated block: 애플리케이션을 위해 사용되도록 명시적으로(explicitly) 보존된 블럭. 할당된 블럭은 애플리케이션에 의해 명시적으로든, 메모리 할당기 자기 자신에 의해 암묵적으로든(implicitly) free 당할 때까지 할당된 상태임.
- free block: available to be alloctated. 앱에 의해 명시적으로(explicitly) 할당되기 전까지는 free함.
동적 메모리 할당기 두 유형; explicit allocators, implicit allocators
- 공통점과 차이점
- 공통점: 두 유형 모두 애플리케이션으로 하여금 명시적으로 블럭을 할당하게 함
- 차이점: 어떤 개체가 할당된 블럭을 free시키는데 책임 소재가 있는지가 다름
- 명시적 할당기 explicit allocators
- 애플리케이션으로 하여금 할당된 블록을 explicitly 하게 free 시키길 요구함
- e.g.: C는
malloc함수를 호출해서 블록을 할당하며,free함수를 호출해서 블록을 반환함
- 묵시적 할당기 implicit allocators(= garbage collectors)
- 할당기로 하여금 언제쯤 할당된 블럭이 더이상 프로그램에 의해 사용되지 않을지 알아내게 함. 그리고 블럭을 free 시킴.
- garbage collection: 사용되지 않은 할당된 블럭을 자동으로 free 시키는 프로세스
- e.g.: List, ML, 자바 같은 고급 언어들은 할당된 블록을 반환시키기 위해 가비지 컬렉션을 이용함. (파이썬도, 자바스크립트도!)
추가) 동적 메모리 할당과 정적 메모리 할당 key point
- 동적 메모리 할당은 프로그램으로 하여금 메모리를 런타임에(at runtime) 할당하게 함. 반면 정적 메모리 할당은 메모리가 컴파일시에(at a complie time) 할당되도록 함.
- 동적 메모리 할당이 정적 메모리 할당보다 더 유연하고 융통성이 있음. 왜냐하면 필요한 만큼 메모리를 할당할 수 있기 때문. 반면 정적 메모리 할당은 모든 메모리가 한번에 할당 됨.
- 동적 메모리 할당이 정적 메모리 할당보다 더 효율적임. 왜냐하면 필요할 때만 메모리를 할당할 수 있기 때문이며, 더 이상 필요하지 않을 때 메모리를 반환할 수 있기 때문.
- 동적 메모리 할당이 정적 메모리 할당보다 더 에러를 일으키기 쉬움. 왜냐하면 메모리 누수와 단편화로 이어질 수 있기 때문.
- 동적 메모리 할당은 정적 메모리 할당보다 더 많은 메모리 오버헤드를 필요로 함. 왜냐하면 메모리 할당과 할당 반환을 관리하는 프로그램이 필요하기 때문.
- 동적 메모리 할당은 메모리 크기에 빈번한 변화가 있는 프로그램에 적합하며, 정적 메모리 할당은 고정적인 메모리 크기를 갖는 프로그램에 적합함.
- 동적 메모리 할당은 연결 리스트, 스택, 큐와 같은 자료 구조를 만들 때 사용 될 수 있으며, 정적 메모리 할당은 배열같은 고정된 크기의 데이터 구조를 만드는데 사용 됨.
9.9.1 malloc과 free 함수
1. malloc 패키지
- C 표준 라이브러리가 사용하는 명시적인 할당기(explicit allocator)
malloc함수를 호출하면 힙으로부터 블록(=가상 메모리의 연속적인 덩어리)을 할당 받음
2. malloc 함수 예제
#include <stdlib.h>
void *malloc(size_t size);
// Returns: 성공적이라면 할당된 블럭에 대한 포인터, 아니라면 에러로써 NULL
- 최소
size바이트를 가진, 연속된 블럭을 가리키는 포인터를 반환. - 이 블록 내에는 어떤 종류의 데이터 객체도 담길 수 있음(→
void의 의미) - 코드가 32비트 모드, 64비트 모드(디폴트) 둘 중 어느 모드에서 동작하도록 컴파일되었는지에 따라 다름
- 32비트 모드: malloc은 주소가 항상 8의 배수인 블록을 리턴
- 64비트 모드: 주소는 항상 16의 배수
malloc이 문제를 만났을 때(e.g.: 프로그램이 사용 가능한 가상메모리보다 더 큰 크기의 메모리 블럭을 요구하는 경우) →NULL리턴 +errno설정errno에 대한 설명 ☞ errno.h - 위키백과, 우리 모두의 백과사전 (wikipedia.org)errono.h는 C의 표준 라이브러리 내의 헤더 파일로,errno는 오류 번호(error number)를 말하며, 오류 코드를 통해 오류 상태를 보고하고 검색하기 위한 매크로를 정의함
malloc은 메모리를 초기화하지 않음 ⇒calloc이란 함수는 할당된 메모리를 0으로 초기화함realloc함수: 이전에 할당된 블럭의 사이즈를 변경하고 싶은 경우 사용함
3. mmap, munmap, sbrk 함수
#include <unistd.h>
int main()
{
void *sbrk(intptr_t incr);
// Returns: 성공한다면 이전의 brk 값을 리턴, 아니라면 -1 리턴 후 ENOMEM으로 errno 설정
}
malloc동적 메모리 할당기는 이 함수들을 이용하여 명시적으로 힙 메모리를 할당하거나 반환sbrk= subtract break- 이 함수는 커널의
brk포인터에incr을 더해서 힙을 늘리거나 줄임 - 성공한다면 이전의 brk 값을 리턴, 아니라면 -1 리턴 후 ENOMEM으로 errno 설정
incr이 0이면,sbrk는 현재의brk값을 리턴sbrk를 음수incr로 호출하면 합법적이기는 하지만, 리턴 값이(이전의 brk 값) 새로운 힙의 탑을 지나서abs(Incr)바이트를 가리키기 때문에 복잡해짐
- 이 함수는 커널의
4. free 함수
// 예제 3
#include <stdlib.h>
int main()
{
void free(void *ptr);
// Returns: nothing
}
- 할당된 힙 블록을 반환함
ptr인자는malloc,calloc,realloc에서 획득한 할당된 블록의 시작을 가리켜야 함!
→ 그렇지 않다면free의 동작은 정의되지 않음
→ 리턴 값이 없기 때문에 무엇이 잘못됐는지 찾기 어려움!
→ 런타임 에러 유발.
5. malloc과 free에 의한 힙 관리

- a single 16-word double-word-aligned free block: a contiguous block of memory containing 16 words of data that is aligned on an address that is a multiple of 8.
- The padded regions:
malloc함수를 사용함으로써 할당 받은 여분의 메모리. 메모리 블럭에 대한 정보를 담기 위해 사용됨(e.g.: 블럭의 사이즈, status) 이 패딩은 메모리 블럭이 제대로 aligned 되어 있도록 하며(이 예제에서는 8바이트 더블 워드 경계에 맞춰 정렬되도록 하기 위해, 즉 워드가 짝수개로 딱 떨어지도록 하기 위해?), 메모리 관리자가 메모리 블럭의 시작과 끝을 쉽고 빠르게 확인할 수 있게 함.
The padded regions refer to the extra memory that is allocated when using the malloc() function in C. This extra memory is used to store data related to the memory block, such as its size and status. This padding ensures that the memory block is aligned correctly and that the memory manager can quickly and easily identify the start and end of the block.
9.9.2 왜 동적 메모리 할당을 사용하는가?
- 프로그램을 실제 실행시키기 전에는 자료 구조의 크기를 알 수 없는 경우가 있기 때문
- 정적 할당(static allocating) 방법에서는, 우리가 직접 자료의 크기를 선언해야 하며, 이때 할당을 요청하는 메모리의 크기는 실제 해당 머신에서 사용할 수 있는 가상메모리의 크기와 무관할 수 있음(즉 실제 가상메모리에서 사용할 수 있는 메모리 크기를 전혀 신경쓰지 않음) → 큰 규모의 소프트웨어 제품에 관리의 어려움이 있음
- 동적 할당시에는 할당해달라고 요청하는 최대 메모리 크기는 사용 가능한 가상메모리의 양에 의해서만 제한 됨
9.9.3 할당기 요구사항과 목표
1. 명시적 할당기(explicit allocator)가 지켜야 하는 제한사항
- 임의의 요청 순서 처리하기
- 프로그램은 '각각의 메모리 반환 요청(
free)은 이전의 할당 요청(malloc)으로 이미 할당된 상태의 블럭에 대해 이루어진다’는 점을 지키면서, 임의적으로(아무때나, 특별한 패턴 없이) 할당과 반환 요청을 할 수 있으므로 이를 처리해야 함
- 프로그램은 '각각의 메모리 반환 요청(
- 요청에 즉시 응답하기
- 할당 요청이 들어오면 즉시 응답해야 함
- 그러므로 할당기는 성능을 향상시키기 위해 요청을 재정렬하거나, buffer 하면 안 된다 (※ buffer란, 데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 그 데이터를 보관하는 것 버퍼 (컴퓨터 과학) - 위키백과, 우리 모두의 백과사전 (wikipedia.org))
- 힙만 사용하기
- 확장성을 갖기 위해(scalable) 할당기가 사용하는 비확장성 자료 구조(any nonscalar data structures)는 힙 자체에 저장되어야 함
- 정렬 요건: 블록 정렬하기(alignment) (※ alignment: single word, double word 등으로 표현 됨)
- 할당기는 블록들이 어떤 종류의 데이터 객체라도 저장할 수 있도록 하는 방식으로 정렬해야 함
- 할당된 블록을 수정하지 않기
- 할당기는 가용 블럭(free block)만을 조작하거나 변경할 수만 있음. 일단 할당된 블럭들을 수정하거나 옮길 수 없음. (할당된 블럭 압축하기 등과 같은 기술 허용 안 됨)
2. 할당기의 목표; 이 두 가지는 종종 상충됨
- 처리량 극대화하기
- 처리량:
- 요청에 걸리는 평균 시간을 최소화하면서 달성
- 최악 실행시간이 가용 블록의 수에 비례하고, 반환 요청의 실행시간이 상수
- 처리량:
- 메모리 이용도를 최대화하기
- 가상 메모리는 무한한 자원이 아님 → 한 시스템에서 모든 프로세스에 의해 할당된 가상메모리의 양은 디스크 내의 스왑 공간(swap space)에 의해 제한된다.
- 최고 이용도 peak utilization를 최대화하면서 달성
- 최고 이용도란 주어진 시간에 할당되고 사용된 최대 메모리의 양. 애플리케이션에 따라, 사용 가능한 메모리의 양에 따라, 달라짐
9.9.4 단편화(Fragmentation)
1. 단편화란?
- 나쁜 힙 이용도의 주요 이유
- 가용(free) 메모리를 사용할 수 없어서 할당 요청을 만족시키지 못하는 현상
2. 두 가지 종류의 단편화
- 내부 단편화(internal fragmentation)
- 할당된 블록이 데이터 자체보다 더 클 때
- 예를 들어
- 요청한 데이터 크기보다 더 큰 크기를 최소 부여 크기로 지정한 경우
- 위의 그림 9.34(b)처럼 정렬 요구사항을 만족시키기 위해 padded region을 갖는 등 블록의 크기를 증가시킬 수도 있음
- 내부 단편화 측정하기
- 할당된 블록의 크기와 데이터 간의 차이의 합으로 구하면 됨
- 외부 단편화(external fragmentation)
- 할당 요청을 만족시킬 수 있는 메모리 공간이 전체적으로 공간을 모았을 때는 충분한 크기가 존재하지만, 단일한 가용블록은 없는 경우
- 그림 9.34(e)에서 2워드 요청이 아니라 8워드 할당 요청이었다면, 8개의 가용 워드는 있음에도 연속적인 8워드의 블록이 없기 때문에 커널에 추가 가상메모리를 요청해야 함
- 외부 단편화 측정하기
- 미래에 어떤 요청 패턴이 들어올 것인지에 따라 달라지므로 예측하기 어려움
- → 따라서 할당기들은 작은 가용 블럭을 많이 갖는 것보다, 큰 가용 블럭을 적게 갖는 방법을 취함
9.9.5 구현 이슈
- 처리량과 이용도 사이에 좋은 균형을 갖는 실용적인 할당기를 만드려면?
- 가용 블럭 구성free block organization: 어떻게 가용 블록을 지속적으로 추적하는가? ☞ 9.9.6절
- 배치placement: 새롭게 할당된 블록을 배치하기 위해 적절한 가용 블록을 어떻게 선택하는가? ☞ 9.9.7절
- 분할splitting: 새롭게 할당된 블록을 가용 블록 안에 위치시킨 후에, 그 가용 블럭의 남은 부분은 어떻게 할 것인가? ☞ 9.9.8절
- 연결coalescing: 방금 free된 블럭들을 가지고 어떻게 할 것인가? ☞ 9.9.10절
9.9.6 묵시적 가용 리스트(implicit free lists) ☞ 실용적인 할당기 조건 1: 블럭들을 지속적으로 추적해야 함
1. 블록의 정보를 담을 구조의 필요성
- 블록 간의 경계를 구분해야 함
- free 블록과 allocated 블록을 구분해야 함
- → 묵시적 가용 리스트 구조
2. 묵시적 가용 리스트implicit free lists
- 묵시적 가용 리스트란?
- 한 블록은 1워드 헤더 + 데이터 + 패딩(선택사항)로 구성
- △ 이러한 포맷을 가진 연속적인 가용/할당 블록의 배열 형태를 묵시적 가용 리스트라고 함
- free block들이 헤더 내의 size 필드에 의해서 암묵적으로(implicitly) 연결됨(사이즈만큼 워드를 건너뛰면 다음 헤더를 방문할 수 있음) → 전체 블럭들을 돌아다니면서 가용 블럭의 집합을 방문할 수 있게 됨
- 묵시적 가용 리스트의 블록 형태
- 헤더
- 블록 크기(헤더 + 데이터 + 패딩) + 블록의 할당/가용 유무를 인코딩
- 더블 워드 정렬 제한조건이 있는 경우, 블록 크기는 항상 8의 배수(4 byte워드 + 4 byte워드)이며, 블록 사이즈를 나타내는 값의 하위 3비트는 항상 0(다른 정보를 표시하기 위해 남겨두는 것으로, 이 경우는 할당/가용 유무를 나타냄)
- 헤더 예시
- 블록 크기 24 바이트 + 할당된 블록;
0x00000018 | 0x1 = 0x00000019 - 블록 크기 40 바이트 + 가용 블록;
0x00000028 | 0x0 = 0x00000028
- 블록 크기 24 바이트 + 할당된 블록;
- 데이터
- 애플리케이션이
malloc을 호출하며 요청한 것
- 애플리케이션이
- 패딩
- 가변적 크기를 가짐
- 패딩을 하는 이유
- 외부 단편화를 극복하기 위한 할당기 전략
- 정렬 요구사항을 만족하기 위해
- 헤더
- 묵시적 가용 리스트의 장단점
- 장점: 단순하다
- 단점: 가용 리스트를 탐색하는 연산의(e.g.: 할당된 블록 배치하기) 비용이 힙에 있는 전체 할당/가용 블럭의 수에 비례함
- 최소 블록 크기
- 시스템의 정렬 요구조건 + 할당기의 블록 포맷 선택에 의해 좌우 됨
- e.g.: 더블 워드 정렬 요구조건 ⇒ 최소 블록 크기는 2워드며, 각 블록의 크기는 2워드(8바이트)의 배수가 됨

9.9.7 할당된 블록의 배치placement: first fit, next fit, best fit 정책 ☞ 실용적인 할당기 조건 2: 새롭게 할당된 블록을 배치하기 위해 적절한 가용 블록을 선택할 수 있어야 함
- 할당된 블록을 배치하기 위해 가용 블록을 검색하는 방법
- first fit: 가용 free 리스트를 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택
- 장점: 리스트의 마지막에 가장 큰 가용 블록을 남겨두는 경향
- 단점: 앞 부분에 작은 가용 블록을 남겨두는 경향이 있어서, 큰 블록을 찾는 경우 검색 시간이 늘어남
- next fit: first fit의 대안. 검색을 리스트의 처음이 아닌 이전 검색이 종료된 지점에서 시작
- 장점: first fit에 비해 매우 빠른 속도. (특히 리스트의 앞 부분에 작은 조각들이 많은 경우)
- 단점: first fit보다 최악의 메모리 이용도
- best fit: 모든 가용 블록을 검사하며 크기가 맞는 가장 작은 블록을 선택
- 장점: first fit, next fit보다 더 좋은 메모리 이용도
- 단점: 묵시적 가용 리스트같이 단순한 구성에서는 힙(즉, 배열)을 완전히 다 검색해야 함. → 다단 가용 리스트 조직(segregated free list) 이라는 대안이 등장(best-fit 정책을 단순화한 것으로 힙을 모두 검색하지 않음)
9.9.8 가용 블록의 분할splitting ☞ 실용적인 할당기 조건 3: 새롭게 할당된 블록을 가용 블록 안에 위치시키고, 그 가용 블럭의 남은 부분을 효율적으로 사용해야 함
- 찾은 가용 블록의 어느 정도를 할당할 것인가?
- 가용 블록 전체 사용하기: 간단하고 빠름 but 내부 단편화 (배치가 잘 이루어져서 크기가 잘 맞은 가용 블럭을 찾았다면, 약간의 내부 단편화는 수용 가능)
- 가용 블럭을 두 부분으로 나누기 : 첫번째 부분은 할당한 블록, 나머지는 새로운 가용 블럭이 됨
9.9.9 추가적인 힙 메모리 획득하기
- 할당기가 요청한 블록을 찾을 수 없을 때
- 메모리에서 물리적으로 인접한 가용 블럭을 연결해서(☞9.9.10절) 더 큰 가용블록을 만들어 냄→ 이래도 안 되면 아래 2번
- 커널에게
sbrk함수를 호출하여 추가적인 힙 메모리 요청 → 추가 메모리를 한 개의 더 큰 가용 블록으로 변환 → 이 블록을 가용 리스트에 삽입 → 요청한 블록을 이 새로운 가용 블록에 배치
(※sbrk함수: 커널의brk포인터에incr을 더해서 힙을 늘리거나 줄임 ☞ 위에서sbrk함수 검색)
9.9.10 가용 블록 연결하기coalescing ☞ 실용적인 할당기 조건 4: 방금 free된 블럭을 효율적으로 사용해야 함
- 오류 단편화false fragmentation
- 할당기가 블록을 free 시킬 때, 이 새롭게 free 된 블록에 인접하여 다른 free 블럭이 있을 수 있음 → 작은 가용 블럭들이 붙어 있게 됨
- 인접한 free 블럭을 합치면 공간이 충분히 큼에도 불구하고, 작은 가용 블럭으로 쪼개져 있어서 할당에 실패하게 되는 경우를 말함
- → 연결coalescing을 통해 인접한 가용 블럭을 연결해준다!
- 언제 연결을 수행해야 할까?
- 즉시 연결: 블록이 반환될 때마다 인접 블록을 통합 (여기서는 즉시 연결 형식을 가정하여 설명함!)
- 장점: 간단하고 상수 시간 내에 수행
- 단점: 블록이 연속적으로 연결 되었다가 바로 또 분할되는 등 불필요한 연결 과정이 있을 수 있음
- 지연 연결: 일정 시간 후에 가용 블록을 연결함
- e.g.: 일부 할당 요청이 실패할 때까지 기다렸다가, 그 후에 전체 힙을 검색해서 모든 가용 블럭 연결
- 빠른 할당기들은 종종 이 연결 형태를 사용
9.9.11 경계 태그로 연결하기: 할당기가 연결coalescing을 구현하는 방법
1. 현재 블럭current block이란?
- 할당기가 free 하려고 하는 블럭
2. 현재 블럭과 next free block의 연결
- 헤더를 사용하는 묵시적 가용 리스트(implicit free list)를 사용하는 경우
- 현재 블럭의 헤더는 다음 블록의 헤더를 가리킴 → 이는 다음 블록이 free인지 아닌지 체크하기 위해 사용 됨
(※ 블럭의 헤더에는 블럭의 사이즈(헤더, 패딩, 데이터 다 포함), 할당/가용 유무를 나타내는 비트 0, 1이 들어 있음) - 다음 블록의 헤더를 확인 한 후, 가용 블럭이라면 현재 헤더에 next free block의 사이즈를 더하고 합치면 끝 → 상수 시간
3. 현재 블럭과 previous free block의 연결
- 위에서 설명한 next free block 방식으로 하려면, 이전 블록의 헤더를 검색하기 위해 현재 블록 도달할 때까지 전체 리스트를 한 바퀴 돌아야함 →
free할 때마다 힙의 크기에 비례하여 시간이 소모됨 → 절대 상수시간 내에 안 됨 - → 경계 태그boundary tags 기법의 등장
4. 경계 태그boundary tags
 (※ 9.9.12 절에서 구현에 사용하는 블록 포맷임!)
(※ 9.9.12 절에서 구현에 사용하는 블록 포맷임!)
- 각 블록의 끝 부분에 footer를 추가함
- 이 footer는 헤더를 복사한 것!
(※ 블럭의 헤더에는 블럭의 사이즈(헤더, 패딩, 데이터 다 포함), 할당/가용 유무를 나타내는 비트 0, 1이 들어 있음) - 결국 현재 블럭에서 1 워드 떨어진 곳에 항상 이전 블럭의 footer가 위치하며, 이를 통해 이전 블럭의 시작 위치, 할당/가용 유무 등을 알 수 있게 됨
- 상수 시간에 이전 블록과 현재 블록을 연결
5. 할당기가 현재 블록을 free 할 때 가능한 케이스(모두 상수 시간내 연결)

- previous, next block 모두 할당: 연결 불가능. 현재 블록의 상태만 할당에서 가용으로 변경
- previous block 할당, next block 가용: next block과 연결. 현재 블록의 헤더, 다음 블럭의 풋터가 두 블럭의 사이즈를 합한 값으로 갱신.
- previous block 가용, next block 할당: previous block과 연결. 이전 블럭의 헤더, 현재 블럭의 풋터가 두 블럭의 사이즈를 합한 값으로 갱신.
- previous, next block 모두 가용: 모든 블럭이 연결 됨. 이전 블럭의 헤더, 다음 블럭의 풋터가 세 블럭의 사이즈를 합한 값으로 갱신.
6. 경계태그 아이디어의 장단점
- 장점: 여러 유형의 할당기, 가용 리스트 구성에도 일반적으로 사용할 수 있을만큼 간단함
- 단점: 각 블록이 헤더, 풋터를 유지해야 함 → 애플리케이션이 많은 작은 크기 블록을 다룰수록 상당한 양의 메모리 오버헤드 발생
(※ 메모리 오버헤드: 시스템이나 프로그램이 직접 필요한 메모리보다 더 많은 메모리를 사용하는 것. 예를 들어, 프로그램이 데이터를 저장하고 처리하도록 설계되었다면, 그 데이터를 저장하는 데 정확히 필요한 메모리보다 더 많은 메모리를 사용할 수 있음. 이렇게 추가적으로 사용되는 메모리를 메모리 오버헤드 함.)- e.g.:
malloc,free를 이용하여 그래프 노드를 생성하고 없앨 때, 보통 노드는 메모리에 몇 개만의 워드를 필요로 하므로 이런 경우 헤더와 풋터가 각 할당된 블록의 절반을 차지하게 됨
- e.g.:
7. 경계태그의 최적화
- 현재 블록의 할당/가용 유무 비트 공간에 이전 블록의 할당/가용 비트를 저장
- → 할당된 블럭은 footer가 없어도 된다
- ⇒ 이전 블럭이 free 일 때만 footer안의 size 필드가 필요하기 때문
9.9.12 종합 설계: 간단한 할당기의 구현
0. intro
- 즉시 경계 태그 연결을 사용하는 묵시적 가용 리스트에 기초한 간단한 할당기의 구현
- 최대 블록 크기는
- 최소 블록 크기는 16 byte (=4 워드)
- 코드는 32비트(
gcc -m32) 또는 64비트(gcc -m64)이며, 프로세스에서 수정 없이 돌 수 있는 것은 64비트 (The code is 64-bit clean, running without modification in 32-bit (gcc -m32) or 64-bit (gcc -m64) processes)
1. 할당기 기본 설계: memlib.c 파일
- 이 파일은 메모리 시스템 모델
- 우리가 설계한 할당기가 기존의 시스템 수준의
malloc패키지와 상관없이 돌아가게 하기 위함 mem_init함수: 힙으로 사용할 수 있는 가상메모리를, 큰 더블 워드로 정렬된 바이트의 배열로 초기화해주는 것mem_start_brk: 힙의 시작부분을 나타내는 포인터 (※ 책에서의mem_heap변수임! )mem_start_brk와mem_brk사이의 바이트들은 할당된 가상메모리mem_brk: 이 변수 다음에 오는 바이트들은 미할당 가상메모리mem_sbrk함수: 추가적인 힙 메모리를 요청함. 시스템sbrk함수와는 달리 힙을 축소하라는 요청을 거부함.
- 우리가 설계한 할당기가 기존의 시스템 수준의
- 묵시적 가용 리스트 & 블록 포맷

- 묵시적 가용 리스트의 형식
- 첫번째 워드: 더블 워드 경계로 정렬된 미사용 패딩용 워드
- 프롤로그 블록: 헤더와 풋터로만 구성된 8바이트 allocated 블록, 초기화 과정에서 생성되며 절대 반환하지 않음
- regular block:
malloc,free를 호출해서 생성된 0개 이상의 일반 블록들 (최소 블록 크기 4 워드) - 에필로그 블록: 헤더만으로 구성된 크기가 0으로 allocated 브록. 힙은 항상 에필로그 블록으로 끝남
- 프롤로그 블록과 에필로그 블록은 왜 존재하는가?
- 연결 과정 동안 가장자리 조건을 없애주기 위한 속임수 아마도 연결 연산에서 에러 방지를 위함이 아닐까
- 할당기는 한 개의 정적(static) 전역변수
heap_listp를 사용하며, 이것은 항상 프롤로그 블록을 가리킴(작은 최적화로 프롤로그 블록 대신 다음 블록을 가리키게 할 수 있음)
- 묵시적 가용 리스트의 형식
2. 가용 리스트 조작을 위한 기본 상수와 매크로
#define CHUNKSIZE (1<<12)가 뭐람?- 1 << 12는 이진수 연산자인 왼쪽 시프트(left shift)를 사용한 것입니다. 왼쪽 시프트 연산은 왼쪽으로 이동한 후, 오른쪽의 빈 자리를 0으로 채우는 연산자입니다. 예를 들어, 1 << 12는 1이라는 수를 왼쪽으로 12번 이동시킨 결과인 값인 4096을 나타냅니다. 이진수로 변환하면 1은 0001이며, 왼쪽 시프트 연산을 하면 0001 << 12는 000000000001이 되고, 이것을 십진수로 변환하면 4096이 됩니다.
3. 초기 가용 리스트 만들기
extend_heap- 새 가용 블록으로 힙을 확장시킴
- 다음의 경우에 호출함
- 힙이 초기화 될 때
mm_malloc이 적당한 fit을 찾지 못했을 때, 정렬을 유지하기 위해extend_heap은 요청한 크기를 인접 2워의 배수(8바이트)로 반올림하며, 그 후에 메모리 시스템으로부터 추가적인 힙 공간을 요청함
- 크기가 더블 워드의 배수인 블록(즉 주소가 8의 배수인)을 리턴함
- 에필로그 블록의 헤더에 곧 이어서 더블 워드 정렬된 메모리 블록을 리턴
- 새 가용블록의 헤더, 풋터를
4. 블록 반환과 연결
mm_free함수bp가 가리키는 블록을 free시키고, 인접한 가용 블록과 9.9.11절에서 설명한 경계 태그 연결 방식으로 연결함- %% [[Zettelkasten/3 자기계발/360 배움/362 프로그래밍/362s 컴퓨터 과학/컴퓨터 시스템 정리 (CSAPP) Chapter 9 가상메모리#9.9.11 경계 태그로 연결하기: 할당기가 연결coalescing을 구현하는 방법|컴퓨터 시스템 정리 (CSAPP) Chapter 9 가상메모리#9.9.11 경계 태그로 연결하기: 할당기가 연결coalescing을 구현하는 방법]] %%
- 에필로그 블록, 프롤로그 블록을 설정함으로써 힙의 시작과 마지막 부분의 블록들의 previous, next 블록을 체크하는 과정의 성능에 도움 ⇒ 그렇지 않으면 매번 블록들이 경계에 위치해있는지 확인해야 하며(드문 케이스인), 더 느리고 에러날 가능성도 커짐
coalesce함수
- 위 그림 9.40의 네 케이스를 구현
5. 블록 할당
mm_malloc함수 호출해서size바이트의 메모리 블록을 요청- 추가적인 요청을 체크한 후, 할당기는 요청한 블록 크기를 조절하여 헤더와 풋터를 위한 공간 확보, 더블 워드 요건 만족
9.9.13 명시적 가용 리스트
9.9.14 분리 가용 리스트
9.10 가비지 컬렉션
9.11 C 프로그램에서의 공통된 메모리 관련 버그(할당기의 잘못된 사용으로 발생할 수 있는 위험한 에러들)
9.12 summary
'컴퓨터 시스템' 카테고리의 다른 글
| 컴퓨터 시스템 정리 (CSAPP) Chapter 11 네트워크 프로그래밍 (0) | 2022.12.10 |
|---|---|
| 컴퓨터 시스템 정리 (CSAPP) Chapter 6 (0) | 2022.12.03 |
| 컴퓨터 시스템 정리 (CSAPP) Chapter 3 Machine-Level Reperesentation of Programs (0) | 2022.11.30 |
| 컴퓨터 시스템 정리 (CSAPP) Chapter 1 A tour of Computer Systems (1) | 2022.11.09 |