- 개인적으로 공부하면서 지속적으로 정보를 추가, 수정, 삭제합니다.
- 정확하지 않은 부분 피드백 주시면 감사합니다.
- 노란색 하이라이트는 블로그 주인의 생각 + 개인적으로 이해가 더 필요한 부분을 표시한 것입니다. 특별히 더 중요한 개념으로 표시한 것이 아닙니다.
- TIL/WIL 노트의 일부를 정리해서 적합한 카테고리의 노트 항목에 추가합니다.
2023-01-03, 2023-01-07
PintOS KAIST GitBook: Project3: Virtual Memory - Introduction
참고: https://casys-kaist.github.io/pintos-kaist/project3/introduction.html
우리의 지금 OS
- 멀티플 스레드
- 적절한 동기화
- 다양한 유저 프로그램을 동시에 load
하지만! 실행될 수 있는 프로그램의 숫자와 크기는 머신의 램 메모리 크기에 의해 제한 됨
Project 3에서는 "무한한 메모리"라는 환상을 만들면서 이러한 제한을 제거할 것
소스파일
- "DO NOT CHANGE"라고 쓰인 부분 수정하지 말아라.
- 모든 페이지는 초기에 uninitialized page로 셋업됨, 그리고 그것은 anonymous pages나 file-backed pages로 바뀜
- 대부분
vm디렉토리, 아니면 이전 프로젝트에서 다뤘던 파일들을 다룰 것 include/devices/block.h,devices/block.c에서는, 섹터 기반 읽기(sector-based read), 블록 디바이스에 대한 쓰기 접근을 제공함. 여기의 인터페이스를 블록 디바이스로서의 ==스왑 파티션(swap partition)==에 접근하기 위해 사용할 것.
메모리 & 스토리지 용어
페이지
- 페이지(= Virtual Page)는 연속적인 가상 메모리 공간으로, 4096바이트(4KB) 크기를 가짐(page size)
- 페이지는 반드시 page-aligned 되어야 함 → 즉, 페이지 사이즈의 배수인 가상 주소로 시작한다
- 그러므로 64비트 가상 주소의 마지막 12비트는 page offset 혹은 offset이다
- 상위 비트(the upper bits)는 페이지 테이블의 인덱스를 가리키는데 사용된다
- 64비트 시스템에서 우리는 4레벨 페이지 테이블을 사용하며, 이는 가상 주소를 이렇게 보이게 만듦
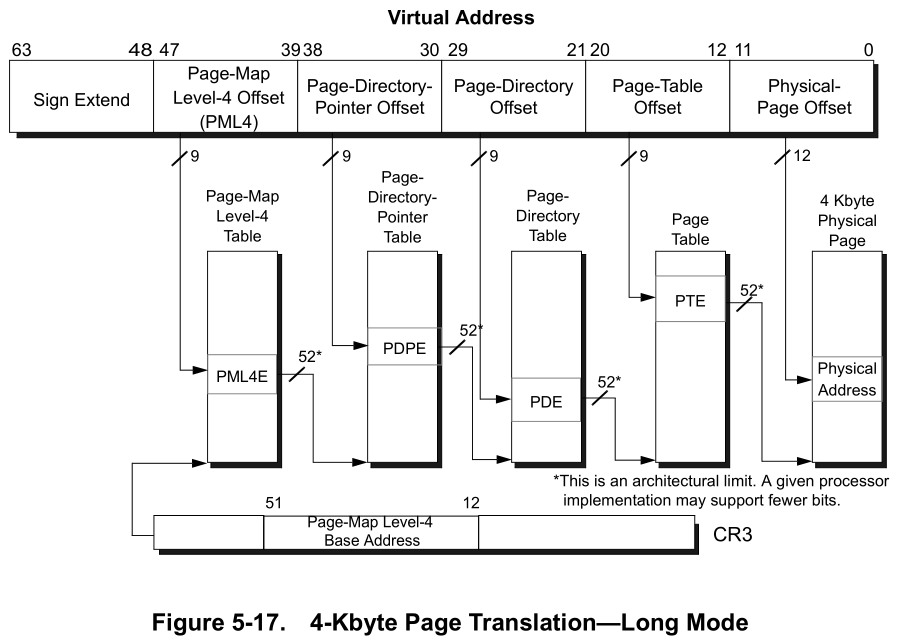 [1]
[1]
- CR3에 PML4로 가는 베이스 주소가 담겨 있고, 그 테이블이 또 다음 테이블의 베이스 주소가 되고 그런 구조로 보임
- 각각의 프로세스는 독립적인 유저 가상 페이지의 집합을 가지고 있음 → 이는 가상 주소
KERN_BASE(0x8004000000) 아래 쪽의 페이지들을 말함 즉 유저영역?! - 반면 커널 가상 페이지는 전역적임(global) → 그러므로 어떤 스레드나 프로세스가 실행되든간에, 똑같은 position에서 위치한다.
- 커널은 유저, 커널 페이지 모두 접근 ⭕
- 하지만 유저 프로세스는 오직 그것의 유저 페이지에만 접근 ⭕
프레임Frames = 물리 프레임physical frame, 페이지 프레임page frame
- 연속적인 물리 메모리의 구역을 말함
- 페이지처럼, 프레임은 반드시 페이지 사이즈(4kb)여야 하고, 페이지 정렬(page-aligned) 되어야 함.
- 그러므로 64비트 물리 주소는 "frame number"와 "프레임 offset(혹은 그냥 offset)"으로 나뉠 수 있음:

- x86-64는 물리 주소의 메모리로 바로 접근할 수 있는 방법을 제공하지 않음 → 하지만 핀토스는 커널 가상 메모리를 바로 물리 메모리로 매핑함으로써, 커널 가상 메모리를 통해 프레임에 접근하도록 했다.
- 커널 가상 메모리의 첫번째 페이지는 물리 메모리의 첫 번째 프레임으로 매핑된다. 두 번째 페이지는 두 번째 프레임으로 매핑된다. 그렇게 계속 매핑된다.
- 핀토스는 물리 주소와 커널 가상 주소간의 번역을 하는 함수를 제공한다. ☞ Virtual Addresses
page tables @threads/mmu.c
- 페이지 테이블은 CPU가 가상 주소를 물리 주소로 번역하기 위해 사용하는 자료구조 → 즉, 페이지에서 프레임으로!
- 페이지 테이블 포맷은 x86-64 아키텍쳐에 의해 결정
- 페이지와 프레임의 관계
 [2]
[2] - 가상주소 & 물리주소
- 가상주소: 페이지 넘버 + 오프셋
- 물리주소: 페이지 테이블에 의해 번역된 프레임 넘버 + 가상 주소의 offset
- 페이지 테이블은 페이지 넘버를 프레임 넘버로 번역 → 이는 물리 주소를 얻기 위해 오른쪽의 수정되지 않은 offset과 합쳐진다 오프셋은 그대로 갖다 쓰는 것 신기하다
swap slots 스왑슬롯
- 스왑 파티션의 디스크 공간에 있는 페이지 크기의 구역
- 슬롯의 위치를 결정하는 하드웨어 제한은 프레임을 위한 것보다 더 융통성 있지만, 스왑 슬롯은 페이지 정렬되는게 좋다 (그렇게 해서 나쁠 점이 없으므로)
자원 관리 overview
다음과 같은 자료구조를 구현해야 한다
- supplemental page table
- 이는 페이지 테이블을 보완함으로서 페이지 폴트를 가능함
- frame table
- 이는 물리 프레임의 **효율적인 희생 정책(eviction policy)**를 구현하도록 함
- swap table
- 이는 스왑 슬롯의 사용을 추적하게 함.
- 반드시 위 세개를 완전히 분리된 자료구조로 구현할 필요는 없음; 전체적으로, 혹은 부분적으로 관련된 자원을 통합하여 하나의 통일된 자료구조를 쓰는 것이 편리할 수도 있다.
- 각각의 자료 구조에 대해서, 당신은 각각의 요소가 어떤 정보를 포함해야 하는지 결정해야 한다.
- 또한 자료구조의 스코프를 결정해야 한다; local(per-process) or global(전체 시스템에 적용되는)
- 그리고 그것의 스코프 안에서 얼마나 많은 instance가 요구되는지도 결정해야 한다 ???
- 설계를 단순화하기 위해, 이런 자료 구조를 non-pageable 메모리(e.g.:
calloc,malloc을 이용한)에 저장할 수도 있음 → 따라서 그 자료구조들 사이의 포인터가 유효한 상태로 유지된다는 것을 확신할 수 있음
성능 관점에서 구현 선택지
구현을 위한 가능한 선택지로는 array, lists, bitmap, hash table이 있다.
- array는 가장 단순한 접근법 but 띄엄띄엄 채워진 어레이는 메모리 낭비
- lists는 또한 단순하지만, 특정 포지션을 찾기 위해 긴 리스트를 traversing하는 것은 시간 낭비
- 어레이와 리스트는 둘 다 resize 될 수 있음, 하지만 list는 좀 더 효율적으로 삽입과 삭제를 지원함
- bitmap 자료구조는
lib/kernel/bitmap.candinclude/lib/kernel/bitmap.h에 있다 - bitmap은 bits의 array → 각각의 bit는 true or false이다
- bitmap은 일반적으로 동일한 리소스의 집합에서 사용을 추적하기 위해 사용된다: 만약 어떤 리소스 n이 사용중이면, 비트맵의 n 비트가 true다
- 핀토스 비트맵은 사이즈가 고정이다. 하지만 resizing을 지원하기 위해 그들의 구현을 extend할 수 있긴 하다.
- 핀토스는 또한 해시 테이블 자료구조도 포함한다
- 핀토스 해시 테이블은 다양한 테이블 사이즈를 아우르며 효율적으로 삽입과 삭제를 지원
- 더 복잡한 자료구조가 더 나은 성능 or 다른 베네핏을 줄 수 있긴 하지만, 그것들은 또한 불필요하게 당신의 구현을 복잡하게 하므로 추천 안함(e.g.: 균형 이진 트리)
Supplemental Page Table 관리하기
 [3]
[3]
SPT는 각각의 페이지에 대한 추가적인 데이터로 페이지 테이블을 보충함
페이지 테이블의 형식에서 오는 한계 때문에 필요함
SPT는 최소 다음 두 가지 목적을 위해 사용됨
- 가장 중요한 것은, 페이지 폴트가 났을 때, 커널이 그곳에 어떤 데이터가 있어야 하는지 알아내기 위해 폴트난 가상 페이지를 SPT에서 찾아본다.
- 두번째로는, 커널은 프로세스가 끝났을 때 어떤 리소스를 free 시켜야 하는지 결정하기 위해 SPT를 참조한다.
SPT 조직하기
원하는 대로 조직할 수 있음
조직하기 위한 두 가지 접근법이 있음: 세그먼트 관점, 페이지 관점.
여기서 세그먼트란 연속적인 페이지의 그룹을 가리킴 → 즉, executable이나 memory-mapped file을 담고있는 메모리 구역
선택적으로, 우리는 SPT의 멤버들을 추적하기 위해 PT 그 자체를 사용할 수도 있다. 그렇게 하기 위해서는 threads/mmu.c에서 핀토스 페이지 테이블 구현을 수정해야 할 것이다. ?? (어드밴스 스튜던트에게만 추천한다)
페이지 폴트 관리하기
SPT의 가장 중요한 사용자는 페이지 폴트 핸들러이다
프로젝트 2에서 페이지 폴트는 항상 커널이나 유저 프로그램의 버그를 가리켰다
프로젝트 3에서는 더이상 그렇지 않으며, 페이지 폴트는 file이나 swap slot에서 가져와져야 하는 페이지를 가리킬 것
우리는 더 복잡한 페이지 폴트 핸들러를 구현해야 함
userprog/exception.c의 페이지 폴트 핸들러 page_fault() 는 vm/vm.c에 있는 우리의 페이지 폴트 핸들러, vm_try_handle_fault()를 호출한다.
우리의 페이지 폴트 핸들러는 대충 다음과 같이 해야한다;
- SPT에서 오류난 페이지를 찾는다.
- 만약 메모리 참조가 유효하면, 페이지에 들어가는 데이터를 찾기 위해 SPT entry를 사용한다. 이는 파일 시스템에 있을수도 있고, swap slot에 있을수도 있고, 혹은 zeroed 페이지 일수도 있음. 공유(즉, Copy-on-Write)를 구현하면 페이지의 데이터가 이미 페이지 프레임에는 있지만 페이지 테이블에는 없을 수도 있다. SPT가 사용자 프로세스가 액세스하려는 주소에서 데이터를 기대해서는 안 된다고 나타내거나, 페이지가 커널 가상 메모리 내에 있거나 액세스가 읽기 전용 페이지에 쓰려는 시도인 경우, 그 접근은 invalid하다. invalid한 접근은 프로세스를 종결시키고, 그에따라 그것의 모든 리소스를 free시킨다.
- 페이지를 저장하기 위해 frame을 얻는다.
- 만약 공유를 구현하려는 경우, 당신이 필요한 데이터가 이미 프레임에 있을 수 있고, 이 경우 해당 프레임을 찾을 수 있어야 함. 즉, 물리 메모리에는 다른 프로세스가 사용하느라 이미 있을 수도 있는데, PTE에는 없을 수도
- 파일 시스템 또는 스왑, 제로화 등에서 데이터를 읽어 프레임으로 가져온다. 만약 공유를 구현하려는 경우, 당신이 필요한 데이터가 이미 프레임에 있을 수 있고, 이 경우 이 단계에서는 어떤 액션도 필요하지 않음
- fault난 가상 주소에 대한 page table entry가 물리적 페이지를 가리키도록 합니다.
프레임 테이블 관리
- 프레임 테이블은 각각의 frame에 대해 하나의 entry를 가진다. 각각의 entry는 페이지를 가리키는 포인터를 가진다. + 우리가 선택적으로 추가할 다른 데이터들.
- frame table은 핀토스로 하여금 더이상 쓸 수 있는 프레임이 없을 때 희생시킬 페이지를 고르도록 함으로서, 효율적으로 희생 정책(eviction policy)를 구현하도록 한다.
- 사용자 페이지를 위해 사용되는 프레임은
palloc_get_page(PAL_USER)을 호출함으로서 "user pool"에서 가져와야 함. 반드시PAL_USER를 사용해야 함. "커널 풀"에서 할당 받지 않도록 하기 위함이며, 만약 그런 경우 몇몇 테스트 케이스에서 실패할 수 있음. 만약 우리가 frame table 구현의 일환으로palloc.c를 수정한다면, 두 pool간의 구별을 유지하도록 해라. - frame table에서 가장 중요한 연산은 사용하지 않는 frame을 얻는 것이다. 이는 frame이 free할 때는 쉽지만, 그렇지 않다면 몇몇 page를 evict 함으로써 frame은 반드시 free 되어야 한다. 만약 swap slot을 더 할당받지 않고서는 어떤 페이지도 evict 될 수 없으면서 swap도 full인 상태라면, panic the kernel.
- 실제 OS들은 이런 상황을 방지하거나 회복하기 위해 다양한 policy를 적용하지만 우리의 구현 범위 넘어감.
- eviction 과정은 다음과 같은 단계를 거침:
- 페이지 교체 알고리즘을 사용하여 축출할 프레임을 선택한다. 아래에 설명된 페이지 테이블의 “accessed” 및 “dirty” 비트가 유용할 것
- 프레임을 참조하는 모든 페이지 테이블에서 프레임에 대한 참조 제거. 공유를 구현하지 않은 경우 단일 페이지만 프레임을 주어진 시간에 참조.
- 필요한 경우, 페이지를 파일 시스템에 쓰거나 스왑합니다. 축출된 프레임은 다른 페이지를 저장하기 위해 사용될 수 있음.
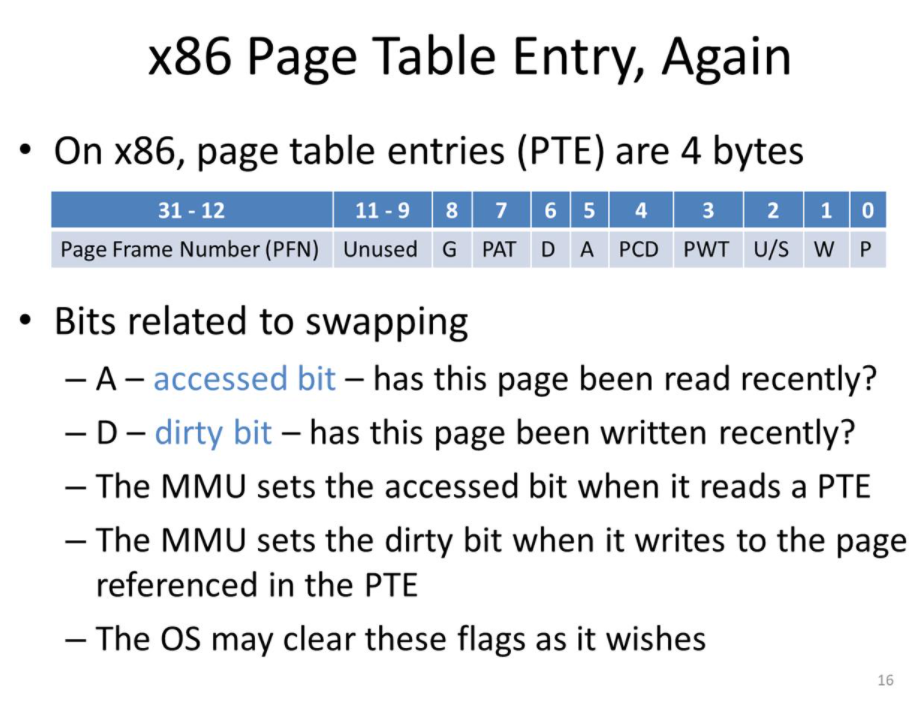
Accessed and Dirty Bits

- 각 페이지에 대한 PTE 속의 bit 한 쌍을 이용한 페이지 교체 알고리즘을 서포트해줌.
- 페이지에 대한 모든 읽기 또는 쓰기 작업에서 CPU는 페이지의 PTE에서 accessed bit\를 1로 설정
- 페이지에 대한 모든 쓰기에서 CPU는 더티 비트\를 1로 설정한다.
- 이러한 bit들을 0으로 초기화하는 것은 CPU가 아니라 OS
aliases란 같은 frame을 가리키는 두 개 혹은 그 이상의 페이지들.- aliased frame에 접근하면, accessed와 dirty 비트는 오로지 하나의 PTE에서만 업데이트 된다(액세스에 사용된 페이지에 대한 entry) 즉, 다른 aliases에 대한 accessed, dirty 비트는 업데이트 되지 않음
- 핀토스에 존재하는 앨리어싱:
- 핀토스에서 모든 유저 가상 페이지는 그것의 커널 가상 페이지로 앨리어싱 되어 있다. 우리는 반드시 이러한 앨리어스들을 관리해야 한다. 예를 들어 우리의 코드는 두 주소 모두에 대해 액세스된 비트와 더티 비트를 확인하고 업데이트할 수 있다. 또는 커널이 유저 가상 주소를 통해서만 사용자 데이터에 액세스하여 문제를 피할 수 있습니다.
- 다른 앨리어스들은 공유를 구현하거나, 우리의 코드에 버그가 있는 경우에만 발생해야 함
- See Section Page Table Accessed and Dirty Bits for details of the functions to work with accessed and dirty bits.
스왑 테이블 관리
- 스왑 테이블은 in-use/free 스왑 슬롯을 나타냄
- 스왑 테이블은 프레임에서 스왑 파티션으로 페이지를 희생시키기 위해 사용가능한 스왑슬롯을 골라낼 수 있어야 함.
- 스왑 슬롯 free는 언제?
- 페이지가 프레임으로 read back 됐거나
- 페이지가 스왑 된 프로세스가 종료됐을 때
- 스왑 공간 만들기
vm/build에서pintos-mkdisk swap.dsk —swap-size=n명령을 사용하여 n-MB의 스왑 파티션을 갖는swap.dsk라는 이름의 디스크를 만든다. 이후swap.dsk를 실행하면 자동으로 추가 디스크로 연결된다. 혹은,—swap-size=n을 이용하여 단일실행에 n MB의 임시 스왑 디스크를 사용할 수도 있다.
- 스왑 슬롯은 미리 할당되어있을 필요가 없음. 즉, eviction에 의해 스왑 슬롯이 필요할 때에만 할당되면 됨. (실행 파일로부터 데이터 페이지 읽고, 프로세스 시작하자마자 스왑 공간에 그 페이지 writing하기❌, 특정 페이지를 저장하기 위해 스왑 공간 예약하기 ❌)
메모리 매핑된 파일 관리
파일 시스템은 read와 write 시스템 콜로 가장 빨리 접근할 수 있음.
두 번째 인터페이스는 mmap 시스템 콜을 이용해 파일을 가상 페이지로 "mapping"하는 것이다.
그러면 그 프로그램은 파일 데이터에 바로 메모리 명령어를 사용할 수 있다.
foo라는 파일이 0x1000 bytes (4 kB, or one page) 길이라고 해보자. 만약 foo가 0x5000부터 시작하는 주소에 매핑된다면, 0x5000…0x5fff 에 대한 어느 메모리 접근이건 foo에 상응하는 바이트에 접근하게 될 것이다.
Here’s a program that uses mmap to print a file to the console.
It opens the file specified on the command line,
maps it at virtual address 0x10000000,
writes the mapped data to the console (fd 1),
unmaps the file.
#include <stdio.h>
#include <syscall.h>
int main (int argc UNUSED, char *argv[])
{
void *data = (void *) 0x10000000; /* Address at which to map. */
int fd = open (argv[1]); /* Open file. */
void *map = mmap (data, filesize (fd), 0, fd, 0); /* Map file. */
write (1, data, filesize (fd)); /* Write file to console. */
munmap (map); /* Unmap file (optional). */
return 0;
}
우리의 서브미션!
우리는 어떤 메모리가 memory mapped file에 의해 사용되는지 추적할 수 있어야 함. 메모리 매핑 테이블이라도 만들어야 하는가?
이것은 mapped region에서 페이지 폴트를 적절히 다루기 위해 필요하다.
그리고 mapped file들이 프로세스 안의 다른 세그먼트를 덮어씌우지 않게 하도록 하기 위해 필요하다.
2023-01-05
널널한개발자 - 프로그래밍을 위한 가상메모리 개요, 메모리 관리 개요, 메모리 오버레이와 스왑, 가상 메모리 페이징 기법의 구현
참고: https://www.youtube.com/watch?v=qk7pfIwcNSU&list=PLXvgR_grOs1DGFOeD792kHlRml0PhCe9l&index=19
https://www.youtube.com/watch?v=-jlzaslp-w4
https://www.youtube.com/watch?v=dtEGd30T8Rk&list=PLXvgR_grOs1DGFOeD792kHlRml0PhCe9l&index=21
https://www.youtube.com/watch?v=d_S2QGQ_rBo&list=PLXvgR_grOs1DGFOeD792kHlRml0PhCe9l&index=25
무엇?
-
절대주소와 상대주소

- 운영체제 영역부터 0으로 계산하면 절대 주소
- 사용자 영역부터 0으로 계산하면(즉, 어떤 기준을 두고 위치를 계산) 40이라고 부르게 되고, 이게 상대 주소 → 논리 주소 공간(logical ≒ virtual)
-
메모리 오버레이(memory overlay)
- 옛날에 사용하던 방식
- 하나의 메모리에 여러 프로그램을 겹겹이 쌓아놓고 실행하는 것
- 요구 페이징과 비슷하나, 요구 페이징은 페이지 단위로 필요할 때마다 로딩/언로딩 하는 전략이라면, 메모리 오버레이는 프로그램이나 데이터의 세그먼트를 한번에 수동으로 로딩/언로딩 함
-
스왑인과 스왑아웃 (혹은 페이지인, 페이지아웃)

- 하드디스크에 스왑 영역(Swap Space)\이라는 보조 기억 장치를 둠
- 물리메모리 + 스왑영역 = 실제 컴퓨터가 사용할 수 있는 메모리 공간
- 스왑 인: CPU 더러 연산해달라고 메모리로 가지고 오는 것
- 스왑 아웃: 잘 안 쓰는 프로그램이니까 빼버리는 것. HDD에 write 하는 것인데 이때 느리다고 많이 체감하게 됨
- e.g. 최대 절전 모드 → RAM에 있던 모든 작업 내용(실제로는 잘 쓰이는 것들만)을 HDD에 옮겨 놓는 것(스왑아웃한 것)
- 이전에는 스왑이 자주 일어났다 → SSD가 등장 → 스왑 아웃 속도가 빨라짐
-
가상메모리는 멀티 프로세싱, 멀티 스레딩 그 이상의 중요도를 갖는 개념
-
컴퓨터의 메모리
- 컴퓨터마다 스펙이 다름 - 메모리 용량이 다름.
- 1차 메모리 RAM, 2차 메모리 SSD
- 메모리의 크기가 서로 다른데… 소프트웨어가 각각의 메모리 스펙에 맞춰 코드를 고친다고 생각하면? → 너무 힘들다 → 실제로 과거 90년대에는 소프트웨어가 인터럽트 핸들링을 했다 → 범용 OS가 등장하면서 그럴 필요가 없어졌다. → 결과적으로 메모리 의존성X OS의 필요성, 가상 메모리의 등장 배경
- 더 중요한 것은, 관리적 측면에서 높은 추상성을 제공 → 보안 → 관리, 통제, 접근 제어가 가능해짐!
-
가상메모리
- 가상 메모리 공간이란 4GB 짜리 배열.
char[429억]같은 → 즉 완전히 선형적인 공간. 이 안에 스택, 힙, 기타 등등 그것들이 다 있다. - 기억 공간 관리의 최소 단위인 1 byte 마다 주소가 붙음
- 만약 이런 관리의 최소 단위가 32 bit라면? 대략 429억 바이트까지 주소가 나옴 → 용량으로 따지면 4GB
- 이런 관리의 최소 단위는 OS가 몇 비트냐, CPU가 몇 비트냐에 의존적 → 가상 메모리 얘기를 할 때는 일단 비트 수부터 먼저 따진다
- OS, CPU 둘 다 64비트? → 2의 64승 - 1 이 가장 큰 수, 이론상 16EB(엑사바이트)까지 가능하지만, OS 스펙이 받쳐줘야 하고, 실제로 이렇게까지 쓰지 못함(이런 이유로 64비트 컴퓨터 시스템 수명이 꽤 오래 갈거라고 예상한다고 함)
- 가상 메모리 공간이란 4GB 짜리 배열.
-
32비트 응용 SW의 경우
- OS와 상관없이 소프트웨어의 주소 체계는 32비트면 충분하다는 것.
- 2GB, 2GB로 VMS(가상 메모리 스페이스)를 자름(메모리 파티션) -> 앞 쪽을 유저 영역, 뒷쪽을 커널 영역, 앞단의 0번지는 무조건 OS가 사용 → 유저가 실제로 사용할 수 있는 영역은 1.8GB 정도
- 기본적으로 커널의 2GB는 잘 논하지 않고, 앞의 2GB (OS+유저 영역)을 주로 논함
-
메모리 매니저(MM)\가 관리하는 메모리 영역 -> RAM + Swap 영역(disk) -> 즉 이것이 쓸 수 있는 메모리의 최대 크기 (둘 중 어느 것을 늘릴 것은 비용과 성능에 대한 이야기. 스왑 영역이 커지면 I/O 효율이 많이 떨어진다고 함. RAM을 늘릴 수록 효율이 더 낫지만 비용이 높아진다고 함. )
- 메모리 매니저란? OS의 프로그램 or 컴포넌트로, 컴퓨터 내의 메모리 할당 및 해제를 도맡음. 각기 다른 프로그램과 데이터가 효율적이고, 충돌을 피하면서 메모리에 잘 저장되도록 함. MMU는 가상 주소를 메모리 내의 물리 주소로의 매핑을 도맡은 하드웨어 컴포넌트.
-
동적주소변환; 즉, 런타임에 주소 체계를 변환한다.
- 주소 체계?
- 세그멘테이션, 페이징
- 물리 메모리에서 메모리 구역을 나누는 걸 세그멘테이션이라고 함. 확인 필요
- 가상 메모리 체계에서 메모리를 일반적으로 4KB 단위로 나누는 것을 페이징이라고 함. 확인 필요
- 모든 프로세스에게 약 2GB의 가상 메모리를 부여 받는데(32비트 가정), 프로세스마다 실제로 사용하는 메모리 크기가 다름 → 페이징, 세그멘테이션 기법 등을 이용하여 OS가 촘촘하게 잘 쓰도록 함.
- 가상메모리에서의 주소 시작은 무조건 0번이다 → 각자의 프로세스의 똑같은 100번지 주소를 참고해도, 각 프로세스의 100번 주소가 가리키는 실제 물리 메모리 구역은 다를 수 있음.
- 여기서 중요한 것은 매핑 테이블: 메모리 매니저가 가지고 있는 자료구조 (e.g.: 프로세스 A는 n번 세그먼트에 있다, 프로세스 D는 스왑됐다, 페이징 시스템인 경우 n번 페이지)
- 스왑됐다; 물리 메모리에 없고 하드 디스크로 옮겨졌다.
- 매핑 테이블은 array일 가능성이 매우 높다. (마치 lookup 테이블처럼 만들어진)
- 가상메모리의 가장 좋은 점! 만약 프로세스 A가 오작동해서 죽었다? 매핑 테이블에서 A와 관련된 entry를 삭제하기만 하면 됨 + 부여된 n번 세그먼트를 여분의 공간으로 빼버리면 됨. 즉 OS의 메모리 매니저가 이러한 것들을 다 알고 있기 때문에 메모리의 신속한 회수가 가능해짐 → 프로세스가 바보 짓을 아무리 많이 해도 메모리를 못 쓰는 일이 벌어지지 않게 됨 → 자원낭비가 적어짐
- 좋은 OS일 수록 앱의 가상화 정도를 높임. (e.g.: 모바일 OS들 아무리 앱을 많이 켜도 )
- 세그멘테이션, 페이징
- 주소 체계?
-
가상 메모리 페이징 기법의 구현
- 메모리를 block 단위로 일정하게 자르는 것 = 페이징
- VMS가 아파트 단지면, 페이지는 동이다. 주소는 호수다. 이 호수를 표현하기 위해 절대적인 기준부터 상대적인 위치를 나타내게 하는데 → 이게 offset
- 페이지 테이블에서 invalid → 매치되는 프레임이 없다 → 페이지 폴트(혹은 세그먼트로 관리되면 세그멘테이션 폴트)
-
가상 메모리 접근 권한
- rwx : read, write, execute
- 권한 비트는 페이지 테이블에 포함되어 있음.
- 그런데 내꺼는 권한을 내 코드로 수정할 수 있음. → 원격 코드 실행 방지를 위해 OS가 DEP를 통해 execution을 막아준다.
- 만약 페이지 테이블에는 write 권한이 없는데, 내가 거기다가 쓰려고 했다?(
*p = 'A') → 페이지 폴트. 액세스 바이올레이션.
왜?
핀토스 프로젝트 3-4를 위한 가상메모리 시스템 이해하기
2023-01-07, 2023-01-08, 2023-01-09, 2023-01-10
PintOS KAIST GitBook: Project3: Virtual Memory - Memory Management (가상 페이지와 물리 프레임 관리하기)
참고: https://casys-kaist.github.io/pintos-kaist/project3/introduction.html
Page Structure and Operations
페이지 연산
- 어떤 페이지냐에 따라 페이지 연산의 루틴이 달라짐 → a) 각각의 함수에 대해 switch-case 구문으로 작성하거나 b) 함수 포인터를 사용하기
- 핀토스 기본 코드에는 페이지 연산을 구현하기 위해 함수 포인터를 소개하고 있는 듯
- 함수 포인터 → 함수, 혹은 메모리 안의 실행가능한 코드를 가리키는 포인터.
- checking 없이 런타임 밸류에 기반해여 함수를 불러 실행할 수 있어서 유용함
- 코드 수준에서는 단순히
destroy(page)를 부르는 것으로 충분하며, 올바른 함수 포인터를 호출함으로서 컴파일러가 페이지 타입에 따른 적절한destroy루틴을 선택하게 될 것. - 예를 들어:
vm_dealloc_page(page)를 호출 →destroy(page)를 호출 → 페이지의 vm_type에 따라 맞는destroy함수를 호출하게 될 것 → 파일이니까file_backed_destroy를 호출하게 될 것
Implement Supplemental Page Table
- 현재 핀토스는
pml4를 이용해 가상 & 물리 메모리 매핑을 관리 중 → 충분하지 않음 - 각각의 페이지에 대한 추가적인 정보를 담기 위해 SPT 필요함 → 페이지 폴트를 다루고 + 리소스 관리를 위해서
PintOS KAIST GitBook: Hash Table
참고: https://javascriptonthego.wordpress.com/2017/05/03/what-is-a-hash-table/
https://guides.codepath.com/compsci/Hash-Tables



Data Types
핀토스 spt 해시 테이블에서 무엇이 key고 무엇이 value인지 알 필요가 있다. 즉 어떤 것을 lookup 하는지 → va : page
- 각각의 해시 테이블 요소는 반드시 key를 포함함
- key란 요소를 구분하고 식별하는 데이터임. key는 해시 테이블의 요소들 간에서 반드시 고유한 값이어야 함. (요소들은 또한 유니크하지 않은 non-key data(== value?)도 가질 수 있다)
- 한 요소가 해시 테이블 안에 존재하는 동안, 그것의 key는 바뀌어선 안됨. "해시 테이블에서 해당 요소 삭제 → key 수정 → 요소 재삽입"으로 할 것
- 각각의 해시 테이블에 대해, key에 작동하는 두 가지 함수를 반드시 작성할 것! 해쉬 함수와, 비교 함수
- For each hash table, you must write two functions that act on keys: a hash function and a comparison function. These functions must match the following prototypes: 해시 함수 등등 깃북 참고하기
PintOS KAIST GitBook: Project3: Virtual Memory - Anonymous Page (무기명 페이지 구현하기)
참고: https://casys-kaist.github.io/pintos-kaist/project3/anon.html
Anonymous Page
- 무기명 페이지란?
- non-disk based image
- anonymous mapping은 backing 파일이나 기기가 없음.
- file-backed page와 달리 어떠한 이름을 가진 파일 소스를 가지고 있지 않다.
- 무기명 페이지는 스택, 힙과 같은 실행 파일에서 사용된다.
- 무기명 페이지를 나타내는 자료구조
anon_h의anon_page- 현재 비어있음
- 필요한 정보들이나 상태를 저장하기 위헤 멤버를 추가해라.
- 또한
strcut page를 참조하면, 페이지에 대한 일반적인 정보를 담고 있는데, 무기명 페이지에 대해서는struct anon_page anon이 페이지 구조에 포함되어 있음을 주목할 것.
Page Initialization with Lazy Loading
- Lazy Loading이란?
- 메모리의 로딩이 필요할 때 실행되는 것. 필요해지기 전까지는 로딩하지 않는 것.
- 즉 페이지는 할당 됨(= 대응하는 페이지 구조체가 있음), 하지만 그것과 연결된 물리 프레임은 없는 상태. 그리고 페이지의 실제 컨텐츠가 아직 로드되지 않은 상태.
- 페이지 폴트가 일어나면, 진짜 그것이 필요하다는 이야기이므로, 이때 페이지의 실제 컨텐츠가 로드 됨! 이때 페이지 초기화?
VM_TYPE에 따른 초기화 과정- 커널의 new page request →
vm_alloc_page_with_initializer호출 됨 - initializer가 새로운 페이지 초기화; 페이지 구조체 할당, 페이지 타입에 따라 적절한 initializer 세팅
- 컨트롤을 다시 사용자 프로그램으로 return
- 유저 프로그램이 실행될 때, 유저 프로그램이 자기가 갖고 있다고 생각하는, 하지만 실제 컨텐츠가 없는 어떤 페이지에 접근하려고 할때 페이지 폴트 발생
- 폴트 핸들링 과정 중에,
uninit_initializer가 호출 됨 → 일전에 미리 세팅해 둔 initializer를 호출 - 무기명 페이지의 initializer는
anon_initializer, file-backed page의 initializer는file_backed_initialzier임
- 커널의 new page request →
- 페이지의 life cycle
- initialize
- (page_fault->lazy-load->swap-in>swap-out->…) 반복
- destroy
- 세 가지 페이지 타입의 life cycle
- 페이지의
VM_TYPE에 따라, 각각의 cycle 단계에서 필요한 과정이 다름. (초기화 과정은 한 예시) - 이러한 각각의 페이지 타입에 따른 life cycle을 구현하는 것이 목표
- 페이지의
Lazy Loading for Executable
- 프로그램 실행 시 lazy loading
- 오직 당장 필요한 메모리 부분만 물리 메모리에 올라감
- 한번에 모든 binary image를 물리 메모리에 올리는 eager loading 방식에 비해 오버헤드를 줄일 수 있음
VM_UNINIT페이지 타입- lazy loading을 지원하기 위함
- 모든 페이지는 처음에
VM_UNINIT페이지로 생성됨 uninit_page는 미초기화된 페이지를 위한 자료구조임- 초기화되지 않은 페이지를 생성, 초기화 및 파괴하는 함수는
uninit.c에서 찾아라(나중에 몇몇 구현도 해야함)- uninit page의 구현. 모든 페이지는 uninit 페이지로 태어남.
- 첫번째 페이지 폴트가 발생하면, 핸들러 체인이
uninit_initialize를 호출함 (page->operations.swap_in) - 그
uninit_initialize함수는 페이지 객체를 초기화함으로서 그 페이지를 특별한 페이지 객체(anon, file, page_cache)로 바꿈. vm_alloc_page_with_initializer함수로부터 인수로 받은 초기화 콜백 함수(lazy_load_segment 인 듯)를 호출함.
- 페이지 폴트 빅 픽쳐
- 페이지 폴트 핸들러
page_fault()는vm_try_handle_fault에게 control을 넘겨줌 - 먼저 유효한 페이지 폴트인지 확인함(
fault_addr가 유효한지) - bogus fault인 경우, 몇몇 컨텐츠를 페이지로 로드
- bogus fault의 예시:
- lazy-loaded page ☞ 지금은 얘만 고려함
- 스왑아웃 된 페이지
- 쓰기 금지된 페이지(CoW 구현 참고)
- lazy loading에 의한 페이지 폴트인 경우:
- 커널은 세그먼트에 lazy load하기 위해
vm_alloc_page_with_initializer에 미리 설정해둔 이니셜라이저 중 하나lazy_load_segment를 호출
- 커널은 세그먼트에 lazy load하기 위해
- bogus fault의 예시:
- 유저 프로그램에게 컨트롤 반환
- 페이지 폴트 핸들러
- requirements (all of the tests in project 2 except fork should be passed.)
vm_alloc_page_with_initializer()구현- 넘겨받은
VM_TYPE에 따른 적절한 이니셜라이저를 fetch하고.uninit_new를 그것과 함께 호출해라!!
- 넘겨받은
setup_stack()수정- 새로운 메모리 관리 시스템에 맞게끔 스택 할당 부분 고치기
- 최초의 스택 페이지는 lazy load 될 필요 없음(=fault 날 때까지 기다릴 필요 없음). → load하는 시점에 명령행 인수를 가지고 할당 + 초기화한다! 셋업스택 이후에 바로 스택 알규먼트가 실행되므로, 한 페이지만 할당 + 초기화 해놓으면 될 듯
- 스택을 식별하는 방법을 제공해야 할수도 있다 "이 페이지는 스택이야"라고 페이지에 표시하는 것!
- page를 마크하기 위해 보조 마커(e.g.
VM_MARKER_0in vm.h 파일)를 사용할 수도 있다
- page를 마크하기 위해 보조 마커(e.g.
vm_try_handle_fault함수 수정spt_find_page를 통해 SPT를 참조함으로서, 오류난 주소에 상응하는 페이지 구조체를 resolve해라!
2023-01-18
project 3 anonymous page 페이지 폴트 에러
참고:
무엇?
Page fault at 0x24: not present error reading page in kernel context.
왜?
hash_insert() 함수의 매개변수로 해시 구조체를 주어야 하는데, spt 구조체를 넣어 준 에러 발견
어떻게?
printf("999999999999999999999999999999.\n"); 를 여기저기 찍어보는 방법으로 해결
bool spt_insert_page(struct supplemental_page_table* spt UNUSED, struct page* page UNUSED)
{
...
if (!(hash_insert(&spt->spt_hash_table, &page->hash_elem))) // "&spt"로만 적어서 에러!
{
succ = true;
}
...
}
project 3 anonymous page ‘pml4_get_page(): assertion is_user_vaddr(uaddr)’ 에러
참고:
무엇?
FAIL tests/userprog/args-none
Kernel panic in run: PANIC at ../../threads/mmu.c:259 in pml4_get_page(): assertion `is_user_vaddr(uaddr)' failed.
Call stack: 0x80042181aa 0x800420d1ad 0x800421c45d 0x8004221512 0x80042214b3 0x800421c7b5 0x800421c292 0x800421bc0f 0x800421b82b 0x8004207435
Translation of call stack:
0x00000080042181aa: debug_panic (lib/kernel/debug.c:32)
0x000000800420d1ad: pml4_get_page (threads/mmu.c:261)
0x000000800421c45d: install_page (userprog/process.c:755)
0x0000008004221512: vm_do_claim_page (vm/vm.c:287)
0x00000080042214b3: vm_claim_page (vm/vm.c:269)
0x000000800421c7b5: setup_stack (userprog/process.c:861)
0x000000800421c292: load (userprog/process.c:558)
0x000000800421bc0f: process_exec (userprog/process.c:273)
0x000000800421b82b: initd (userprog/process.c:85)
0x0000008004207435: kernel_thread (threads/thread.c:417)
왜?
install_page의 매개변수로 가상 주소와 kva를 넣어주는데,
그 주소를 가리키는 포인터를 넣을 것인지, 그 주소 자체를 넣어야 하는지 혼동이 있었음.
어떻게?
ASSERT(is_kernel_vaddr(stack_bottom)); 처럼 주소를 확인하면서 디버깅
static bool vm_do_claim_page(struct page* page)
{
...
if ((install_page(page->va, frame->kva, page->writable))) // &page->va, &frame->kva 로 되어 있었음
{
return swap_in(page, frame->kva);
}
...
}
'크래프톤정글 > PintOS' 카테고리의 다른 글
| 크래프톤정글 PintOS; Project 3 Diagram (Anonymous Page 까지) (0) | 2023.01.21 |
|---|---|
| 크래프톤정글 PintOS; Project 1, 2 Diagram (0) | 2023.01.21 |
| 크래프톤정글 8주차; WIL - PintOS Project 2 User Program (1) | 2023.01.21 |
| 크래프톤정글 8주차; WIL - PintOS Project 1 Threads (0) | 2022.12.22 |